一文读懂 Spring Data Jpa!
有很多读者留言希望松哥能好好聊聊 Spring Data Jpa!其实这个话题松哥以前零零散散的介绍过,在我的书里也有介绍过,但是在公众号中还没和大伙聊过,因此本文就和大家来仔细聊聊 Spring Data 和 Jpa!
故事的主角
Jpa
1. JPA是什么
- Java Persistence API:用于对象持久化的 API
- Java EE 5.0 平台标准的 ORM 规范,使得应用程序以统一的方式访问持久层
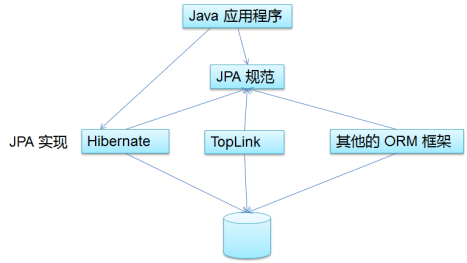
2. JPA和Hibernate的关系
- JPA 是 Hibernate 的一个抽象(就像JDBC和JDBC驱动的关系);
- JPA 是规范:JPA 本质上就是一种 ORM 规范,不是ORM 框架,这是因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由 ORM 厂商提供实现;
- Hibernate 是实现:Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现
- 从功能上来说, JPA 是 Hibernate 功能的一个子集
3. JPA的供应商
JPA 的目标之一是制定一个可以由很多供应商实现的 API,Hibernate 3.2+、TopLink 10.1+ 以及 OpenJPA 都提供了 JPA 的实现,Jpa 供应商有很多,常见的有如下四种:
- Hibernate
JPA 的始作俑者就是 Hibernate 的作者,Hibernate 从 3.2 开始兼容 JPA。 - OpenJPA
OpenJPA 是 Apache 组织提供的开源项目。 - TopLink
TopLink 以前需要收费,如今开源了。 - EclipseLink
4. JPA的优势
- 标准化: 提供相同的 API,这保证了基于JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
- 简单易用,集成方便: JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注解;JPA 的框架和接口也都非常简单。
- 可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
- 支持面向对象的高级特性: JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
5. JPA包含的技术
- ORM 映射元数据:JPA 支持 XML 和 JDK 5.0 注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
- JPA 的 API:用来操作实体对象,执行CRUD操作,框架在后台完成所有的事情,开发者从繁琐的 JDBC 和 SQL 代码中解脱出来。
- 查询语言(JPQL):这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序和具体的 SQL 紧密耦合。
Spring Data
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。Spring Data 具有如下特点:
- SpringData 项目支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库) - SpringData 项目所支持的关系数据存储技术:
JDBC
JPA - Spring Data Jpa 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!
- 框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
主角的故事
Jpa 的故事
为了让大伙彻底把这两个东西学会,这里我就先来介绍单纯的Jpa使用,然后我们再结合 Spring Data 来看 Jpa如何使用。
整体步骤如下:
1.使用 IntelliJ IDEA 创建项目,创建时选择 JavaEE Persistence ,如下: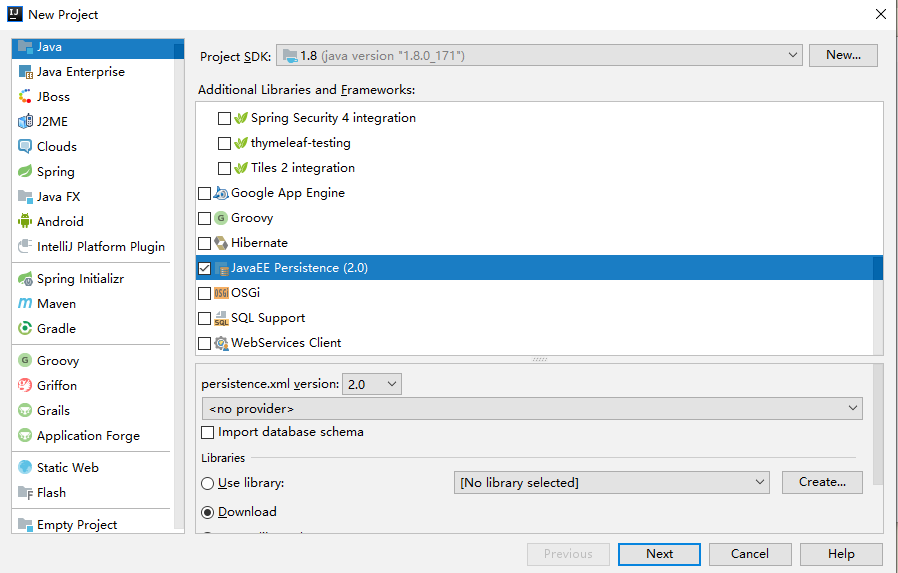
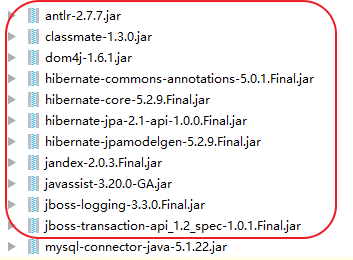
2.创建成功后,添加依赖jar,由于 Jpa 只是一个规范,因此我们说用Jpa实际上必然是用Jpa的某一种实现,那么是哪一种实现呢?当然就是Hibernate了,所以添加的jar,实际上来自 Hibernate,如下:
3.添加实体类
接下来在项目中添加实体类,如下:
1 |
|
首先@Entity注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,@Entity注解的name属性表示自定义生成的表名。@Id注解表示这个字段是一个id,@GeneratedValue注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用@Column注解,去配置字段的名称,长度,是否为空等等。
4.创建 persistence.xml 文件
JPA 规范要求在类路径的 META-INF 目录下放置persistence.xml,文件的名称是固定的
1 |
|
注意:
- persistence-unit 的name 属性用于定义持久化单元的名字, 必填。
- transaction-type:指定 JPA 的事务处理策略。RESOURCE_LOCAL:默认值,数据库级别的事务,只能针对一种数据库,不支持分布式事务。如果需要支持分布式事务,使用JTA:transaction-type=”JTA”
- class节点表示显式的列出实体类
- properties中的配置分为两部分:数据库连接信息以及Hibernate信息
- 执行持久化操作
1 | EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("NewPersistenceUnit"); |
这里首先根据配置文件创建出来一个 EntityManagerFactory ,然后再根据 EntityManagerFactory 的实例创建出来一个 EntityManager ,然后再开启事务,调用 EntityManager 中的 persist 方法执行一次持久化操作,最后提交事务,执行完这些操作后,数据库中旧多出来一个 t_book 表,并且表中有一条数据。
关于 JPQL
- JPQL语言,即 Java Persistence Query Language 的简称。JPQL 是一种和 SQL 非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的 SQL 查询,从而屏蔽不同数据库的差异。JPQL语言的语句可以是 select 语句、update 语句或delete语句,它们都通过 Query 接口封装执行。
- Query接口封装了执行数据库查询的相关方法。调用 EntityManager 的 createQuery、create NamedQuery 及 createNativeQuery 方法可以获得查询对象,进而可调用 Query 接口的相关方法来执行查询操作。
- Query接口的主要方法如下:
- int executeUpdate(); | 用于执行update或delete语句。
- List getResultList(); | 用于执行select语句并返回结果集实体列表。
- Object getSingleResult(); | 用于执行只返回单个结果实体的select语句。
- Query setFirstResult(int startPosition); | 用于设置从哪个实体记录开始返回查询结果。
- Query setMaxResults(int maxResult); | 用于设置返回结果实体的最大数。与setFirstResult结合使用可实现分页查询。
- Query setFlushMode(FlushModeType flushMode); | 设置查询对象的Flush模式。参数可以取2个枚举值:FlushModeType.AUTO 为自动更新数据库记录,FlushMode Type.COMMIT 为直到提交事务时才更新数据库记录。
- setHint(String hintName, Object value); | 设置与查询对象相关的特定供应商参数或提示信息。参数名及其取值需要参考特定 JPA 实现库提供商的文档。如果第二个参数无效将抛出IllegalArgumentException异常。
- setParameter(int position, Object value); | 为查询语句的指定位置参数赋值。Position 指定参数序号,value 为赋给参数的值。
- setParameter(int position, Date d, TemporalType type); | 为查询语句的指定位置参数赋 Date 值。Position 指定参数序号,value 为赋给参数的值,temporalType 取 TemporalType 的枚举常量,包括 DATE、TIME 及 TIMESTAMP 三个,,用于将 Java 的 Date 型值临时转换为数据库支持的日期时间类型(java.sql.Date、java.sql.Time及java.sql.Timestamp)。
- setParameter(int position, Calendar c, TemporalType type); | 为查询语句的指定位置参数赋 Calenda r值。position 指定参数序号,value 为赋给参数的值,temporalType 的含义及取舍同前。
- setParameter(String name, Object value); | 为查询语句的指定名称参数赋值。
- setParameter(String name, Date d, TemporalType type); | 为查询语句的指定名称参数赋 Date 值,用法同前。
- setParameter(String name, Calendar c, TemporalType type); | 为查询语句的指定名称参数设置Calendar值。name为参数名,其它同前。该方法调用时如果参数位置或参数名不正确,或者所赋的参数值类型不匹配,将抛出 IllegalArgumentException 异常。
JPQL 举例
和在 SQL 中一样,JPQL 中的 select 语句用于执行查询。其语法可表示为:select_clause form_clause [where_clause] [groupby_clause] [having_clause] [orderby_clause]
其中:
- from 子句是查询语句的必选子句。
- select 用来指定查询返回的结果实体或实体的某些属性。
- from 子句声明查询源实体类,并指定标识符变量(相当于SQL表的别名)。
- 如果不希望返回重复实体,可使用关键字 distinct 修饰。select、from 都是 JPQL 的关键字,通常全大写或全小写,建议不要大小写混用。
在 JPQL 中,查询所有实体的 JPQL 查询语句很简单,如下:select o from Order o 或 select o from Order as o
这里关键字 as 可以省去,标识符变量的命名规范与 Java 标识符相同,且区分大小写,调用 EntityManager 的 createQuery() 方法可创建查询对象,接着调用 Query 接口的 getResultList() 方法就可获得查询结果集,如下:
1 | Query query = entityManager.createQuery( "select o from Order o"); |
其他方法的与此类似,这里不再赘述。
Spring Data 的故事
在 Spring Boot 中,Spring Data Jpa 官方封装了太多东西了,导致很多人用的时候不知道底层到底是怎么配置的,本文就和大伙来看看在手工的Spring环境下,Spring Data Jpa要怎么配置,配置完成后,用法和 Spring Boot 中的用法是一致的。
基本环境搭建
首先创建一个普通的Maven工程,并添加如下依赖:
1 | <dependencies> |
这里除了 Jpa 的依赖之外,就是Spring Data Jpa 的依赖了。
接下来创建一个 User 实体类,创建方式参考 Jpa中实体类的创建方式,这里不再赘述。
接下来在resources目录下创建一个applicationContext.xml文件,并配置Spring和Jpa,如下:
1 | <context:property-placeholder location="classpath:db.properties"/> |
这里和 Jpa 相关的配置主要是三个,一个是entityManagerFactory,一个是Jpa的事务,还有一个是配置dao的位置,配置完成后,就可以在 org.sang.dao 包下创建相应的 Repository 了,如下:
1 | public interface UserDao extends Repository<User, Long> { |
getUserById表示根据id去查询User对象,只要我们的方法名称符合类似的规范,就不需要写SQL,具体的规范一会来说。好了,接下来,创建 Service 和 Controller 来调用这个方法,如下:
1 |
|
这样,就可以查询到id为1的用户了。
Repository
上文我们自定义的 UserDao 实现了 Repository 接口,这个 Repository 接口是什么来头呢?
首先来看 Repository 的一个继承关系图:
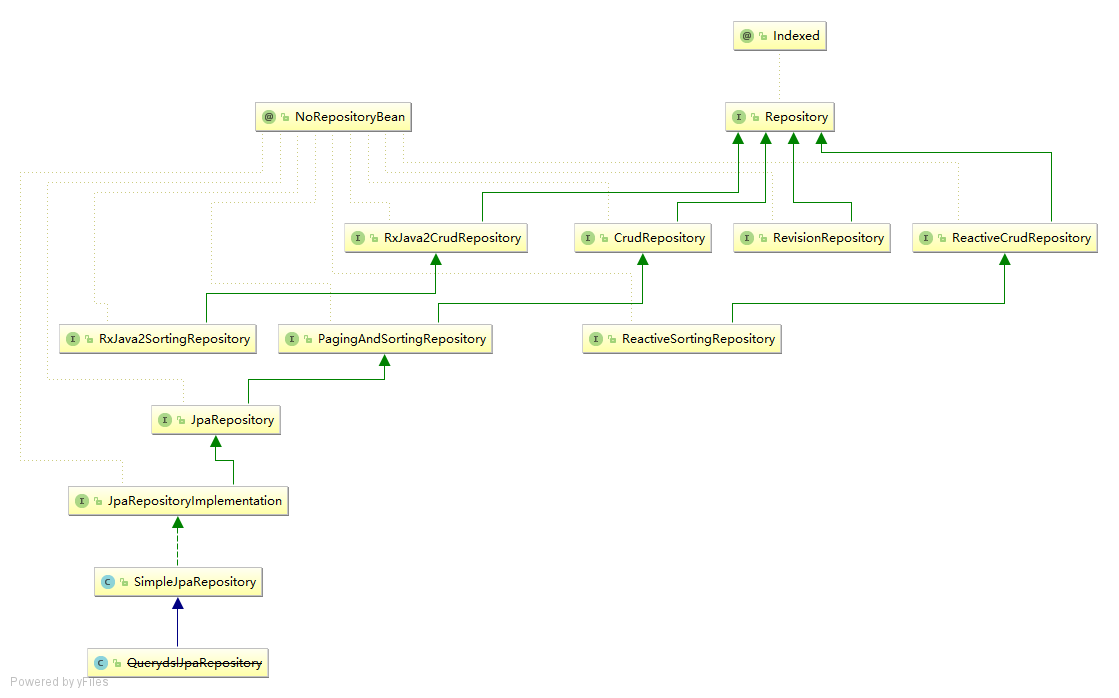
可以看到,实现类不少。那么到底如何理解 Repository 呢?
- Repository 接口是 Spring Data 的一个核心接口,它不提供任何方法,开发者需要在自己定义的接口中声明需要的方法
public interface Repository<T, ID extends Serializable> { } - 若我们定义的接口继承了 Repository, 则该接口会被 IOC 容器识别为一个 Repository Bean,进而纳入到 IOC 容器中,进而可以在该接口中定义满足一定规范的方法。
- Spring Data可以让我们只定义接口,只要遵循 Spring Data 的规范,就无需写实现类。
- 与继承 Repository 等价的一种方式,就是在持久层接口上使用 @RepositoryDefinition 注解,并为其指定 domainClass 和 idClass 属性。像下面这样:
1 |
|
基础的 Repository 提供了最基本的数据访问功能,其几个子接口则扩展了一些功能,它的几个常用的实现类如下:
- CrudRepository: 继承 Repository,实现了一组 CRUD 相关的方法
- PagingAndSortingRepository: 继承 CrudRepository,实现了一组分页排序相关的方法
- JpaRepository: 继承 PagingAndSortingRepository,实现一组 JPA 规范相关的方法
- 自定义的 XxxxRepository 需要继承 JpaRepository,这样的 XxxxRepository 接口就具备了通用的数据访问控制层的能力。
- JpaSpecificationExecutor: 不属于Repository体系,实现一组 JPA Criteria 查询相关的方法
方法定义规范
1.简单条件查询
- 按照 Spring Data 的规范,查询方法以 find | read | get 开头
- 涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性以首字母大写
例如:定义一个 Entity 实体类:
1 | class User{ |
使用And条件连接时,条件的属性名称与个数要与参数的位置与个数一一对应,如下:
1 | findByLastNameAndFirstName(String lastName,String firstName); |
- 支持属性的级联查询. 若当前类有符合条件的属性, 则优先使用, 而不使用级联属性. 若需要使用级联属性, 则属性之间使用 _ 进行连接.
查询举例:
1.按照id查询
1 | User getUserById(Long id); |
2.查询所有年龄小于90岁的人
1 | List<User> findByAgeLessThan(Long age); |
3.查询所有姓赵的人
1 | List<User> findByUsernameStartingWith(String u); |
4.查询所有姓赵的、并且id大于50的人
1 | List<User> findByUsernameStartingWithAndIdGreaterThan(String name, Long id); |
5.查询所有姓名中包含”上”字的人
1 | List<User> findByUsernameContaining(String name); |
6.查询所有姓赵的或者年龄大于90岁的
1 | List<User> findByUsernameStartingWithOrAgeGreaterThan(String name, Long age); |
7.查询所有角色为1的用户
1 | List<User> findByRole_Id(Long id); |
2.支持的关键字
支持的查询关键字如下图:
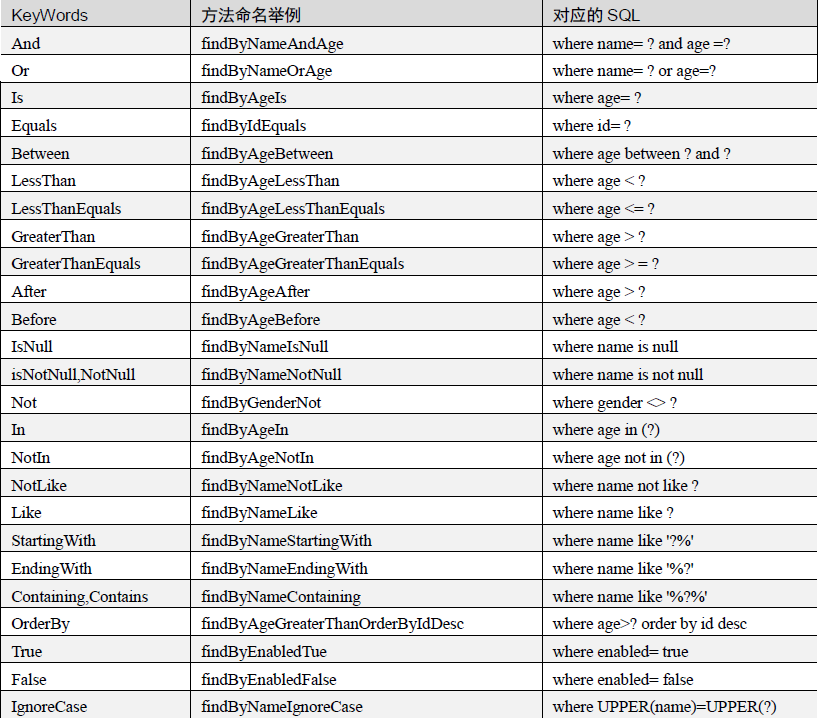
3.查询方法流程解析
为什么写上方法名,JPA就知道你想干嘛了呢?假如创建如下的查询:findByUserDepUuid(),框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc:
- 先判断 userDepUuid (根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
- 从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为查询实体的一个属性;
- 接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 “ Doc.user.depUuid” 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 “Doc.user.dep.uuid” 的值进行查询。
- 可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在属性之间加上 “_” 以显式表达意图,比如 “findByUser_DepUuid()” 或者 “findByUserDep_uuid()”
- 还有一些特殊的参数:例如分页或排序的参数:
1 | Page<UserModel> findByName(String name, Pageable pageable); |
@Query注解
有的时候,这里提供的查询关键字并不能满足我们的查询需求,这个时候就可以使用 @Query 关键字,来自定义查询 SQL,例如查询Id最大的User:
1 |
|
如果查询有参数的话,参数有两种不同的传递方式:
1.利用下标索引传参,索引参数如下所示,索引值从1开始,查询中 ”?X” 个数需要与方法定义的参数个数相一致,并且顺序也要一致:
1 |
|
2.命名参数(推荐):这种方式可以定义好参数名,赋值时采用@Param(“参数名”),而不用管顺序:
1 |
|
查询时候,也可以是使用原生的SQL查询,如下:
1 |
|
@Modifying注解
涉及到数据修改操作,可以使用 @Modifying 注解,@Query 与 @Modifying 这两个 annotation一起声明,可定义个性化更新操作,例如涉及某些字段更新时最为常用,示例如下:
1 |
|
注意:
- 可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作. 注意: JPQL 不支持使用 INSERT
- 方法的返回值应该是 int,表示更新语句所影响的行数
- 在调用的地方必须加事务,没有事务不能正常执行
- 默认情况下, Spring Data 的每个方法上有事务, 但都是一个只读事务. 他们不能完成修改操作
说到这里,再来顺便说说Spring Data 中的事务问题:
- Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
- 对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上添加 @Transactional 注解。
- 进行多个 Repository 操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在Service 层实现对多个 Repository 的调用,并在相应的方法上声明事务。
好了,关于Spring Data Jpa 本文就先说这么多。
