数据库分库分表,都有哪些分片规则?
上次和大伙聊了 MyCat 的安装,今天来说一个新的话题,就是数据库的分片。
当我们把 MyCat + MySQL 的架构搭建完成之后,接下来面临的一个问题就是,数据库的分片规则:有那么多 MySQL ,一条记录通过 MyCat 到底要插入到哪个 MySQL 中?这就是我们今天要讨论的问题。
关于数据库分库分表的问题,我们前面还有几篇铺垫的文章,阅读前面的文章有助于更好的理解本文:
- 提高性能,MySQL 读写分离环境搭建(一)
- 提高性能,MySQL 读写分离环境搭建(二)
- MySQL 只能做小项目?松哥要说几句公道话!
- 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下!
- What?Tomcat 竟然也算中间件?
- 分布式数据库中间件 MyCat 搞起来!
基本概念
逻辑库
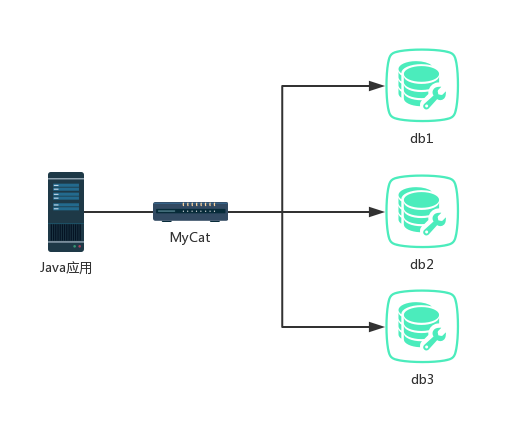
一般来说,对于应用而言,数据库中间件是透明的,应用并不需要去了解中间件复杂的运作过程,中间件对应用来说就是透明的,我们操作中间件就像操作一个普通的 MySQL 一样,这就是 MyCat 的优势之一。
但是我们毕竟操作的不是 MySQL ,而是 MyCat ,MyCat 中的数据库并不真正存储数据,数据还是存储在 MySQL 中,因此,我们可以将 MyCat 看作是一个或者多个数据库集群构成的逻辑库。
逻辑表
逻辑表又有几种不同的划分:
- 逻辑表
既然有逻辑库,那么就会有逻辑表。
因为数据库分片之后,本来存储在一张表中的数据现在被分散到 N 张表中去了,但是在应用程序眼里,还是只有一张表,它也只操作这一张表,这张表并不真正存储数据,数据存储在 N 张物理表中,这个并不真正存储数据的表称之为逻辑表。
- 分片表
分片表,是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。
- 非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
- ER 表
关系型数据库是基于实体关系模型之上,通过其描述了真实世界中事物与关系,Mycat 中的 ER 表即是来源于此。根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组保证数据 join 不会跨库操作。
表分组是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
- 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特性:
- 变动不频繁
- 数据量总体变化不大
- 数据规模不大,很少有超过数十万条记录
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以 MyCat 中通过数据冗余来解决这类表的 join ,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。
数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
分片节点
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
MyCat 提供的分片规则有如下几种:
- 分片枚举
- 固定分片 hash 算法
- 范围约定
- 取模
- 按日期(天)分片
- 取模范围约束
- 截取数字做 hash 求模范围约束
- 应用指定
- 截取数字 hash 解析
- 一致性 hash
- 按单月小时拆分
- 范围求模分片
- 日期范围 hash 分片
- 冷热数据分片
- 自然月分片
实践
这里向大家简单介绍 5 种规则。
global
有一些表,数据量不大,也不怎么修改,主要是查询操作,例如系统配置表,这一类表我们可以使用 global 这种分片规则。global 的特点是,该表会在所有的库中都创建,而且每一个库中都保存了该表的完整数据。具体配置方式,就是在 schema.xml 的 table 节点中添加一个 type 属性,值为 global:

配置完成后,重启 mycat
1 | ./bin/mycat restart |
重启完成后,要删除之前已经创建的 t_user 表,然后重新创建表,创建完成后,向表中插入数据,可以看到,db1、db2 以及 db3 中都有数据了。

这里 虽然查询出来的记录只有一条,实际上 db1、db2 以及 db3 中都有该条记录。
总结:global 适合于 数据量不大、以查询为主、增删改较少的表。
sharding-by-intfile
sharding-by-intfile 这个是枚举分片,就是在数据表中专门设计一个字段,以后根据这个字段的值来决定数据插入到哪个 dataNode 上。
注意,在配置 sharding-by-intfile 规则时,一定要删除 type=”global” ,否则配置不会生效。具体配置如下:

配置完成后,还需要指定枚举的数据。枚举的数据可以在 rule.xml 中查看。
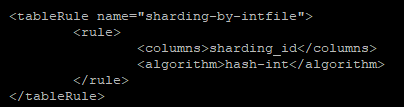
在 rule.xml 文件中,首先找到 tableRule 的名字为 sharding-by-intfile 的节点,这个节点中定义了两个属性,一个是 columns 表示一会在数据表中定义的枚举列的名字(数据表中一会需要创建一个名为 sharding_id 的列,这个列的值决定了该条数据保存在哪个数据库实例中),这个名字可以自定义;另外一个属性叫做 algorithm ,这是指 sharding-by-intfile 所对应的算法名称。根据这个名称,可以找到具体的算法:

还是在 rule.xml 文件中,我们找到了 hash-int ,class 表示这个算法对应的 Java 类的路径。第一个属性 mapFile 表示相关的配置文件,从这个文件名可以看出,这个文件 就在 conf 目录下。
打开 conf 目录下的 partition-hash-int.txt 文件,内容如下:

前面的数字表示枚举的值 ,后面的数字表示 dataNode 的下标,所以前面的数字可以自定义,后面的数字不能随意定义。
配置完成后,重启 MyCat ,然后进行测试:
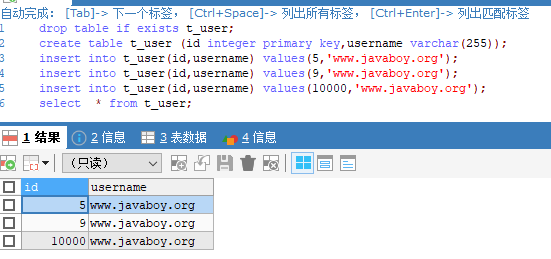
1 | drop table if exists t_user; |
执行完后,sharding_id 对应值分别为 0 、1 、2 的记录分别插入到 db1 、db2 以及 db3 中。
auto-sharding-long
auto-sharding-long 表示按照既定的范围去存储数据。就是提前规划好某个字段的值在某个范围时,相应的记录存到某个 dataNode 中。
配置方式,首先修改路由规则:

然后去 rule.xml 中查看对应的算法了规则相关的配置:

可以看到,默认是按照 id 的范围来划分数据的存储位置的,对应的算法就是 rang-long 。
继续查看,可以找到算法对应的类,以及相关的配置文件,这个配置文件也在 conf 目录下,打开该文件:
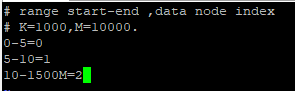
如上配置,表示 当 id 的取值在 0-5之间时,将数据存储到 db1 中,当 id 在 5-10 之间时,存储到 db2 中,当 id 的取值在 10-1500W 之间时,存储到 db3 中。
配置完成后,重启 MyCat ,测试:
mod-long
取模:根据表中的某一个字段,做取模操作。根据取模的结果将记录存放在不同的 dataNode 上。这种方式不需要再添加额外字段。

然后去 rule.xml 中配置一下 dataNode 的个数。

可以看到,取模的字段是 id ,取模的算法名称是 mod-long ,再看具体的算法:

在具体的算法中,配置了 dataNode 的个数为 3。
然后保存退出,重启 MyCat,进行测试:

sharding-by-murmur
前面介绍的几种方式,都存在一个问题,如果数据库要扩容,之前配置会失效,可能会出现数据库查询紊乱。因此我们要引入一致性 hash 这样一种分片规则,可以解决这个问题。具体配置和前面一样:

另外需要注意,在 rule.xml 中修改默认 dataNode 的数量:
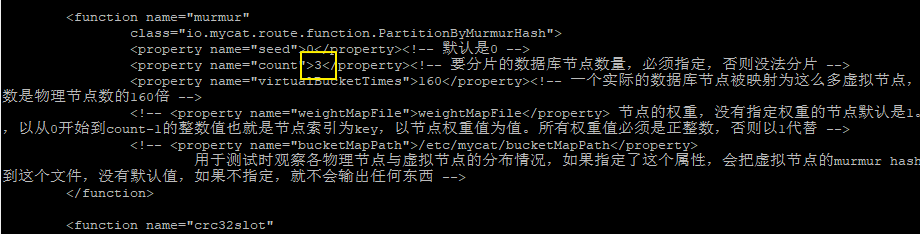
修改完后,重启 MyCat ,进行测试。
好了,本文主要向大家介绍了 MyCat 的五种不同的切片规则。有问题欢迎留言讨论。
参考资料:
