Spring Boot2 系列教程(二十四)Spring Boot 整合 Jpa
Spring Boot 中的数据持久化方案前面给大伙介绍了两种了,一个是 JdbcTemplate,还有一个 MyBatis,JdbcTemplate 配置简单,使用也简单,但是功能也非常有限,MyBatis 则比较灵活,功能也很强大,据我所知,公司采用 MyBatis 做数据持久化的相当多,但是 MyBatis 并不是唯一的解决方案,除了 MyBatis 之外,还有另外一个东西,那就是 Jpa,松哥也有一些朋友在公司里使用 Jpa 来做数据持久化,本文就和大伙来说说 Jpa 如何实现数据持久化。
Jpa 介绍
首先需要向大伙介绍一下 Jpa,Jpa(Java Persistence API)Java 持久化 API,它是一套 ORM 规范,而不是具体的实现,Jpa 的江湖地位类似于 JDBC,只提供规范,所有的数据库厂商提供实现(即具体的数据库驱动),Java 领域,小伙伴们熟知的 ORM 框架可能主要是 Hibernate,实际上,除了 Hibernate 之外,还有很多其他的 ORM 框架,例如:
- Batoo JPA
- DataNucleus (formerly JPOX)
- EclipseLink (formerly Oracle TopLink)
- IBM, for WebSphere Application Server
- JBoss with Hibernate
- Kundera
- ObjectDB
- OpenJPA
- OrientDB from Orient Technologies
- Versant Corporation JPA (not relational, object database)
Hibernate 只是 ORM 框架的一种,上面列出来的 ORM 框架都是支持 JPA2.0 规范的 ORM 框架。既然它是一个规范,不是具体的实现,那么必然就不能直接使用(类似于 JDBC 不能直接使用,必须要加了驱动才能用),我们使用的是具体的实现,在这里我们采用的实现实际上还是 Hibernate。
Spring Boot 中使用的 Jpa 实际上是 Spring Data Jpa,Spring Data 是 Spring 家族的一个子项目,用于简化 SQL、NoSQL 的访问,在 Spring Data 中,只要你的方法名称符合规范,它就知道你想干嘛,不需要自己再去写 SQL。
关于 Spring Data Jpa 的具体情况,大家可以参考一文读懂 Spring Data Jpa
工程创建
创建 Spring Boot 工程,添加 Web、Jpa 以及 MySQL 驱动依赖,如下:
工程创建好之后,添加 Druid 依赖,完整的依赖如下:
1 | <dependency> |
如此,工程就算创建成功了。
基本配置
工程创建完成后,只需要在 application.properties 中进行数据库基本信息配置以及 Jpa 基本配置,如下:
1 | # 数据库的基本配置 |
注意这里和 JdbcTemplate 以及 MyBatis 比起来,多了 Jpa 配置,Jpa 配置含义我都注释在代码中了,这里不再赘述,需要强调的是,最后一行配置,默认情况下,自动创建表的时候会使用 MyISAM 做表的引擎,如果配置了数据库方言为 MySQL57Dialect,则使用 InnoDB 做表的引擎。
好了,配置完成后,我们的 Jpa 差不多就可以开始用了。
基本用法
ORM(Object Relational Mapping) 框架表示对象关系映射,使用 ORM 框架我们不必再去创建表,框架会自动根据当前项目中的实体类创建相应的数据表。因此,我这里首先创建一个 User 对象,如下:
1 |
|
首先 @Entity 注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,@Entity 注解的 name 属性表示自定义生成的表名。@Id 注解表示这个字段是一个 id,@GeneratedValue 注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用 @Column 注解,去配置字段的名称,长度,是否为空等等。
做完这一切之后,启动 Spring Boot 项目,就会发现数据库中多了一个名为 t_user 的表了。
针对该表的操作,则需要我们提供一个 Repository,如下:
1 | public interface UserDao extends JpaRepository<User,Integer> { |
这里,自定义 UserDao 接口继承自 JpaRepository,JpaRepository 提供了一些基本的数据操作方法,例如保存,更新,删除,分页查询等,开发者也可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在 Spring Data 中,只要按照既定的规范命名方法,Spring Data Jpa 就知道你想干嘛,这样就不用写 SQL 了,那么规范是什么呢?参考下图:
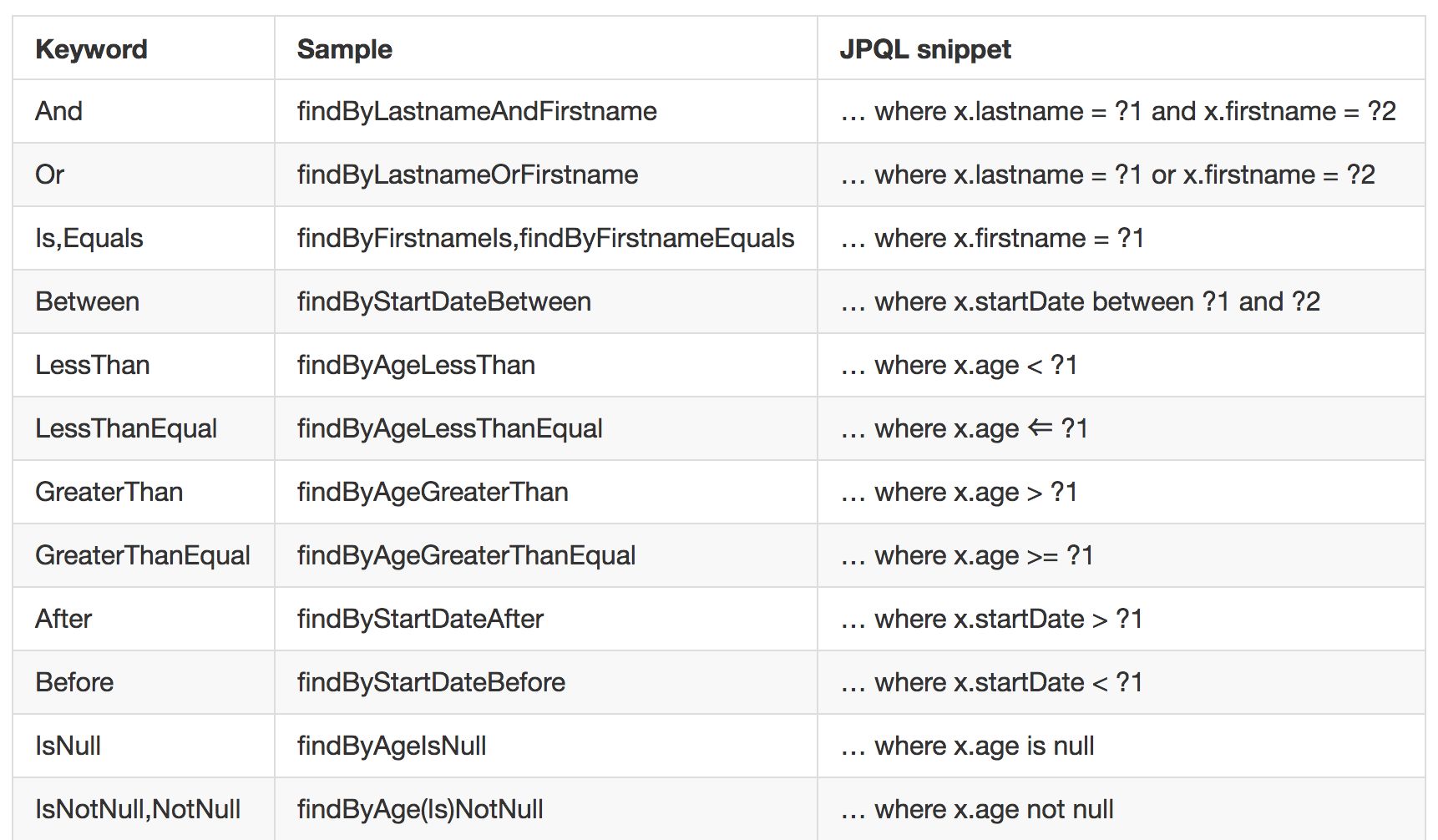
当然,这种方法命名主要是针对查询,但是一些特殊需求,可能并不能通过这种方式解决,例如想要查询 id 最大的用户,这时就需要开发者自定义查询 SQL 了。
如上代码所示,自定义查询 SQL,使用 @Query 注解,在注解中写自己的 SQL,默认使用的查询语言不是 SQL,而是 JPQL,这是一种数据库平台无关的面向对象的查询语言,有点定位类似于 Hibernate 中的 HQL,在 @Query 注解中设置 nativeQuery 属性为 true 则表示使用原生查询,即大伙所熟悉的 SQL。上面代码中的只是一个很简单的例子,还有其他一些点,例如如果这个方法中的 SQL 涉及到数据操作,则需要使用 @Modifying 注解。
好了,定义完 Dao 之后,接下来就可以将 UserDao 注入到 Controller 中进行测试了(这里为了省事,就没有提供 Service 了,直接将 UserDao 注入到 Controller 中)。
1 |
|
如此之后,即可查询到需要的数据。
好了,本文的重点是 Spring Boot 和 Jpa 的整合,这个话题就先说到这里。
多说两句
在和 Spring 框架整合时,如果用到 ORM 框架,大部分人可能都是首选 Hibernate,实际上,在和 Spring+SpringMVC 整合时,也可以选择 Spring Data Jpa 做数据持久化方案,用法和本文所述基本是一样的,Spring Boot 只是将 Spring Data Jpa 的配置简化了,因此,很多初学者对 Spring Data Jpa 觉得很神奇,但是又觉得无从下手,其实,此时可以回到 Spring 框架,先去学习 Jpa,再去学习 Spring Data Jpa,这是给初学者的一点建议。
相关案例已经上传到 GitHub,欢迎小伙伴们们下载:https://github.com/lenve/javaboy-code-samples
