Jpa 中的一对一、一对多没搞明白的话,总会觉得有点绕,今天咱们来简单聊聊这个话题。
1. 一对一
比如说一个学校有一个地址,一个地址只有一个学校。
那么我们可以按照如下方式来设计类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Data
@Entity
@Table(name = "t_address")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer aid;
private String province;
private String city;
private String area;
private String phone;
@OneToOne(cascade = CascadeType.ALL)
private School school;
}
@Data
@Entity
@Table(name = "t_school")
public class School {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
private String name;
@OneToOne(cascade = CascadeType.ALL)
private Address address;
}
|
一对一的关系,可以只在 School 中维护,也可以只在 Address 中维护,也可以两者都维护,具体哪种,那就看需求了。
在上面的例子中,我们在 School 和 Address 中都通过 @OneToOne 注解来维护了一对一的关系。
cascade 用来配置级联操作,有如下取值:
- ALL:所有操作
- PERSIST:级联添加
- MERGE:级联更新
- REMOVE:级联删除
- REFRESH:级联刷新
根据自己需求选择合适的就行。
这样,最终创建出来的 t_school 表和 t_address 表中,会分别多出来一个字段 address_aid 和 school_sid,这两个字段都是外键,正是通过外键,将两张表中不同的记录关联起来。
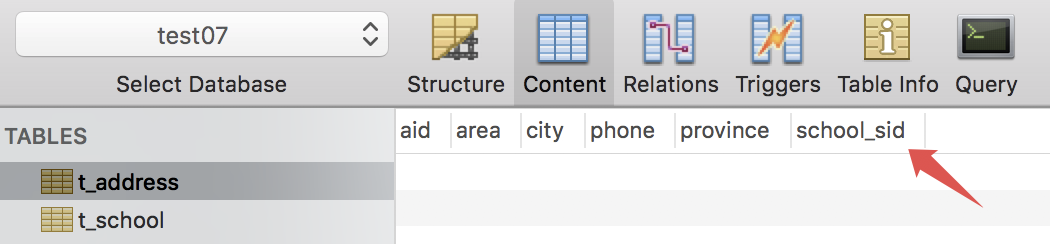
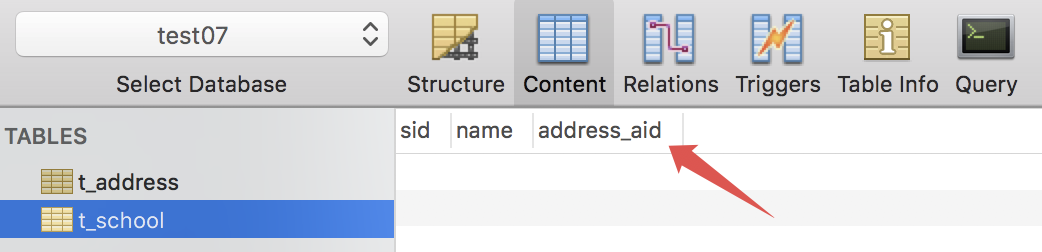
有的人可能不习惯这种自动添加的字段,那也可以自定义该字段,反正该字段总是要有的,自定义的方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Data
@Entity
@Table(name = "t_address")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer aid;
private String province;
private String city;
private String area;
private String phone;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "sid",referencedColumnName = "sid")
private School school;
@Column(insertable = false,updatable = false)
private Integer sid;
}
@Data
@Entity
@Table(name = "t_school")
public class School {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
private String name;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "aid",referencedColumnName = "aid")
private Address address;
@Column(insertable = false,updatable = false)
private Integer aid;
}
|
在 Address 中自定义一个 sid,并设置该字段不可添加和修改,然后通过 @JoinColumn 注解去指定关联关系,@JoinColumn 注解中的 name 表示的是当前类中的属性名,referencedColumnName 表示的则是 School 类中对应的属性名。
在 School 类中做相似的操作。
最后启动项目去观察 MySQL 中生成的表。
2. 一对多
一个班级中有多个学生,而一个学生只属于一个班级,我们可以这样来定义实体类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Data
@Table(name = "t_student")
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
private String name;
@ManyToOne(cascade = CascadeType.ALL)
private Clazz clazz;
}
@Data
@Table(name = "t_clazz")
@Entity
public class Clazz {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer cid;
private String name;
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.EAGER)
private List<Student> students;
}
|
Student 和 Clazz 的关系是多对一,用 @ManyToOne 注解,Clazz 和 Student 的关系是一对多,用 @OneToMany 注解。
Student 和 Clazz 的关系是多对一,将来的 t_student 表中会多出来一个属性 clazz_cid,通过这个外键将 Student 和 Clazz 关联起来。如果我们不想要自动生成的 clazz_cid,那么也可以自定义,方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Data
@Table(name = "t_student")
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
private String name;
@ManyToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "cid")
private Clazz clazz;
@Column(insertable = false,updatable = false)
private Integer cid;
}
|
定义一个 cid 属性,并设置为不可编辑和不可添加,然后通过 @JoinColumn 注解配置 cid 属性为外键。
Clazz 和 Student 的关系是一对多,这个是通过一个自动生成的第三张表来实现的,如下:

3. 测试
3.1 添加测试
先来个一对一的添加测试,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public interface SchoolRepository extends JpaRepository<School,Integer> {
}
@SpringBootTest
class JpaOneToManyApplicationTests {
@Autowired
SchoolRepository schoolRepository;
@Test
void contextLoads() {
School school = new School();
school.setSid(1);
school.setName("哈佛大学");
Address address = new Address();
address.setAid(1);
address.setProvince("黑龙江");
address.setCity("哈尔滨");
address.setArea("某地");
address.setPhone("123456");
school.setAddress(address);
schoolRepository.save(school);
}
}
|
在这个测试过程中,关联关系是由 t_school 一方来维护了,因此将来填充的外键是 t_school 中的 aid。添加结果如下图:
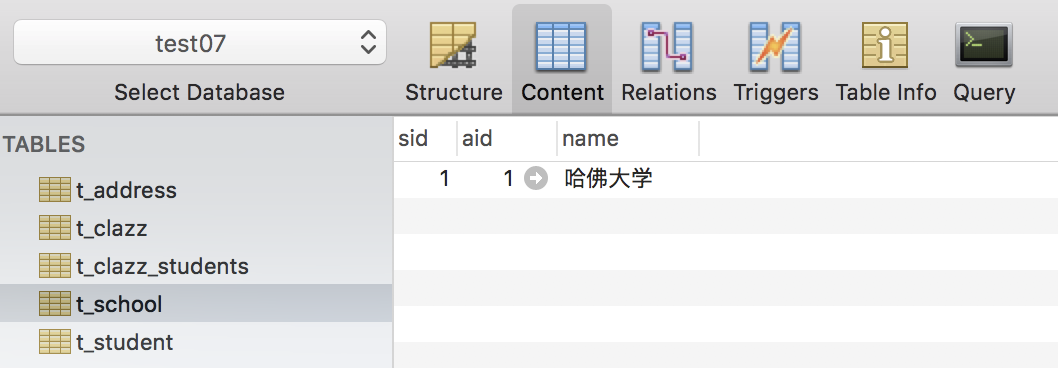
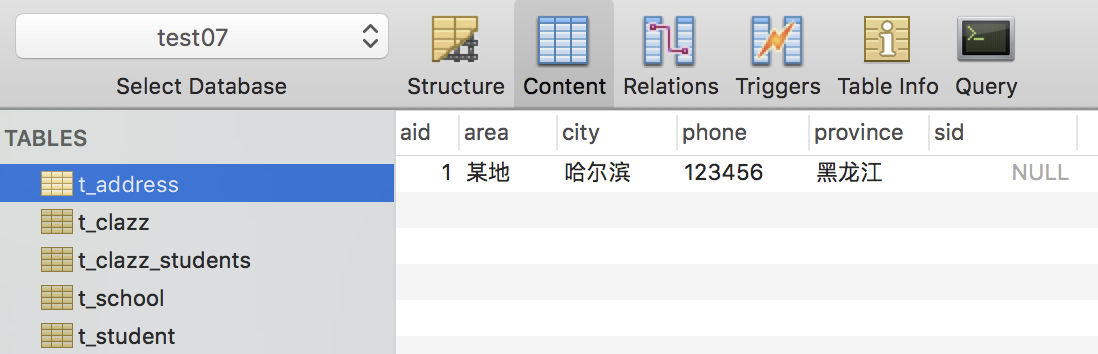
这是一个简单的添加案例。
更新也是调用 save 方法,更新的时候会先判断这个 id 是否存在,存在的话就更新,不存在就添加。
再来看班级的添加,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public interface ClazzRepository extends JpaRepository<Clazz,Integer> {
}
@Autowired
ClazzRepository clazzRepository;
@Test
void test02() {
Clazz c = new Clazz();
c.setCid(1);
c.setName("三年级二班");
List<Student> students = new ArrayList<>();
Student s1 = new Student();
s1.setSid(1);
s1.setName("javaboy");
students.add(s1);
Student s2 = new Student();
s2.setSid(2);
s2.setName("张三");
students.add(s2);
c.setStudents(students);
clazzRepository.save(c);
}
|
注意,添加的是班级,所以班级和学生之间关系就由第三张表来维护,而不是由学生来维护。
3.2 查询测试
再来一个简单的查询,假设我们现在想根据省份来搜索学校,如下:
1
2
3
4
5
6
7
8
9
10
| public interface SchoolRepository extends JpaRepository<School,Integer> {
List<School> findSchoolByAddressProvince(String province);
}
@Autowired
SchoolRepository schoolRepository;
@Test
void test01() {
List<School> list = schoolRepository.findSchoolByAddressProvince("黑龙江");
System.out.println("list = " + list);
}
|
松哥给大家捋一下 Spring Data 如何解析上面自定义的查询方法:
- 首先截取掉 findSchoolByAddressProvince 的前缀,剩下 AddressProvince。
- 检查 School 是否有 addressProvince 属性,有就按照该属性查询,对于我们的案例,并没有 addressProvince 属性,所以继续下一步。
- 从右侧驼峰开始拆分,拆掉第一个驼峰后面的内容,我们这里拆分之后只剩下 Address 了,判断 School 是否存在 Address 属性,不存在就继续重复该步骤,继续切掉右侧第一个驼峰。
- 在上文案例中,School 中有 address 属性,所以接下来就去检查 address 中是否有 province 属性,因为我们这里只剩下一个 province 了,如果剩下的字符串类似于 provinceAaaBbb 这种,那么继续按照第三步去解析。
上面这个写法有一个小小的风险,假设 School 中刚好就有一个属性叫做 addressProvince,那么此时的分析就会出错。所以,对于上面的查询,我们也可以定义成如下方式:
1
2
3
| public interface SchoolRepository extends JpaRepository<School,Integer> {
List<School> findSchoolByAddress_Province(String province);
}
|
此时就不会产生歧义了,系统就知道 province 是 address 的属性了。
再来一个班级的查询,如下:
1
2
3
4
5
6
7
| public interface ClazzRepository extends JpaRepository<Clazz,Integer> {
}
@Test
void test03() {
List<Clazz> list = clazzRepository.findAll();
System.out.println("list = " + list);
}
|
如果在查询的过程中,需要对学生进行排序,可以添加如下属性:
1
2
3
4
5
6
7
8
9
10
11
12
| @Data
@Table(name = "t_clazz")
@Entity
public class Clazz {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer cid;
private String name;
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.EAGER)
@OrderBy("sid desc")
private List<Student> students;
}
|
通过 @OrderBy(“sid desc”) 可以设置查询的 student 排序。
好啦,几个小小的案例,希望对大家有所帮助,公众号后台回复 jpa02,获取本文案例下载链接。
