Spring Boot 整合定时任务,可以动态编辑的定时任务!
定时任务,松哥之前写过多篇文章和大家介绍,上次还自己 DIY 了一个可以动态编辑的定时任务,还录了一个配套视频:

相关的资料链接戳这里:
不过我们当时自己写的这个不支持分布式环境,想要支持倒也不是啥难事,弄一个 zookeeper 或者 redis 作为公共的信息中心,里边记录了定时任务的各种运行情况,有了这个就能支持分布式环境了。
今天咱们不自己写了,我们来看一个现成的框架:ElasticJob,有一个跟他齐名的 xxljob,这个咱们以后再抽空介绍。
1. ElasticJob
1.1 简介
ElasticJob 是一个分布式作业调度解决方案,它的官网是:
Elastic Job 的前身是由当当开源的一款分布式任务调度框架 dd-job,不过在 2020 年 5 月 28 日加入到了 Apache 基金会,成为 Apache 下的一个开源项目:
ElasticJob 通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。
使用 ElasticJob 能够让开发工程师不再担心任务的线性吞吐量提升等非功能需求,使他们能够更加专注于面向业务编码设计;同时,它也能够解放运维工程师,使他们不必再担心任务的可用性和相关管理需求,只通过轻松的增加服务节点即可达到自动化运维的目的。
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。
其中 ElasticJob-Lite 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务:
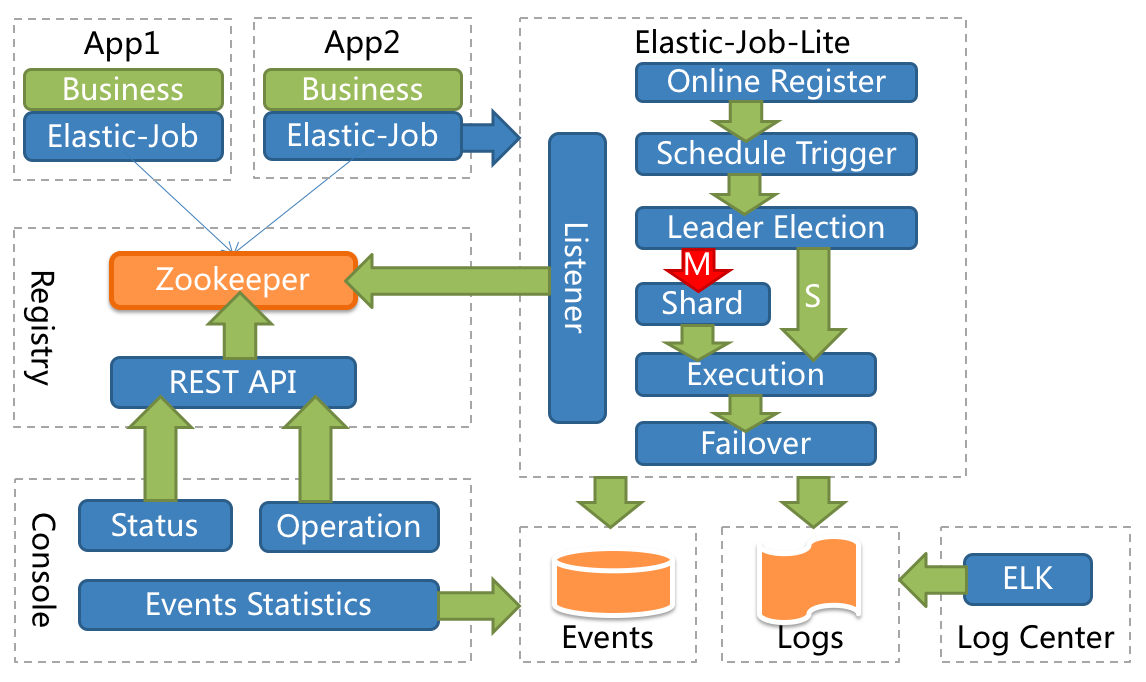
ElasticJob-Cloud 则采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能:

ElasticJob-Lite VS ElasticJob-Cloud:
| ElasticJob-Lite | ElasticJob-Cloud | |
|---|---|---|
| 无中心化 | 是 | 否 |
| 资源分配 | 不支持 | 支持 |
| 作业模式 | 常驻 | 常驻 + 瞬时 |
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署(即 ElasticJob-Lite 和 ElasticJob-Cloud 使用相同的 API,主要是部署方式不同而已)。
1.2 功能列表
弹性调度
- 支持任务在分布式场景下的分片和高可用
- 能够水平扩展任务的吞吐量和执行效率
- 任务处理能力随资源配备弹性伸缩
资源分配
- 在适合的时间将适合的资源分配给任务并使其生效
- 相同任务聚合至相同的执行器统一处理
- 动态调配追加资源至新分配的任务
作业治理
- 失效转移
- 错过作业重新执行
- 自诊断修复
作业依赖(TODO)
- 基于有向无环图(DAG)的作业间依赖
- 基于有向无环图(DAG)的作业分片间依赖
作业开放生态
- 可扩展的作业类型统一接口
- 丰富的作业类型库,如数据流、脚本、HTTP、文件、大数据等
- 易于对接业务作业,能够与 Spring 依赖注入无缝整合
可视化运维平台(https://github.com/apache/shardingsphere-elasticjob-ui)
- 作业管控端
- 作业执行历史数据追踪
- 注册中心管理
2. 实践
说了这么多,接下来我们通过一个简单的案例来体验一把 ElasticJob 吧。毕竟有代码,感觉更真实。
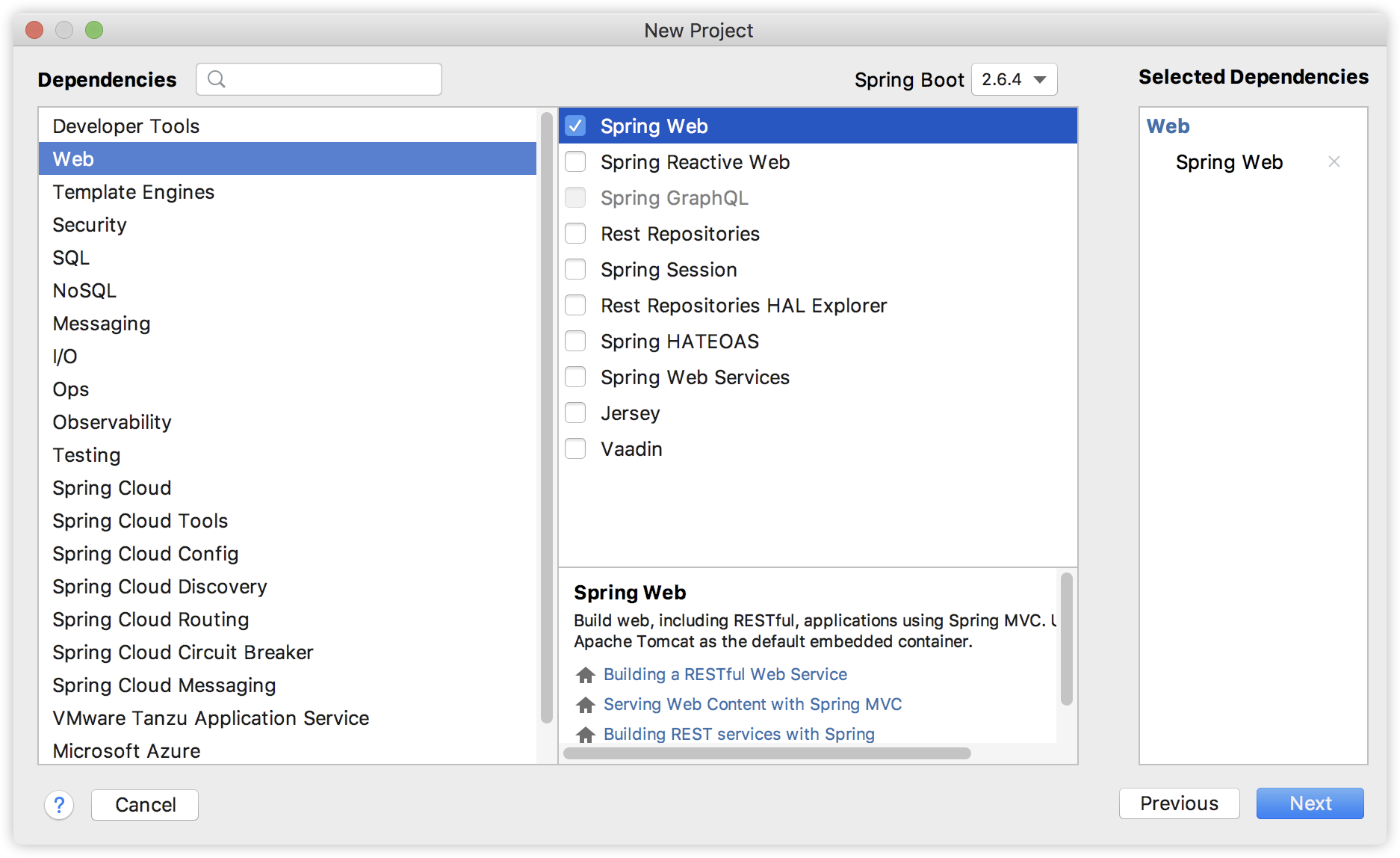
首先我们创建一个 Spring Boot 工程,引入 Web 依赖:
然后手动加入 ElasticJob 的 starter:
1 | <dependency> |
接下来我们创建一个作业,作业有几种不同的创建方式,我们先来看一种基于实现 SimpleJob 接口创建的作业:
1 | /** |
当定时任务执行的时候,execute 方法会被触发,其中参数 ShardingContext 中保存着定时任务相关的参数,这些参数都是我们在 application.properties 中配置的,我们继续来看:
1 | elasticjob.reg-center.server-lists=zoo1:2181,zoo2:2182,zoo3:2183 |
这里的配置分为两大类:
- 注册中心配置
- 定时任务配置
使用 ElasticJob 需要注册中心 zookeeper,这个也好理解,因为 ElasticJob 支持任务在分布式场景下的分片和高可用,所以必然需要一个调度中心,这个 zk 就是调度中心。我这里开启了一个 zk 集群,里边有三个实例,三个 zk 地址之间用 , 隔开。同时我们还要配置一个 namespace,这个 namespace 的作用是防止不同应用的定时任务冲突了,我们给每个应用取一个不同于其他应用的 namespace,这样就不用担心冲突了。
接下来是配置作业。
配置作业的前缀统一是 elasticjob.jobs,紧接着就是作业的名称,这个作业名称可以随意配置,但是最好能一眼看出来是哪个作业,MyFirstJob#execute 方法中的 shardingContext.getJobName() 获取到的就是这个值。
我们这里一共配置了六个属性,我来一一解释下:
- elastic-job-class:作业的全路径。
- cron:cron 表达式。
- sharding-total-count:分片的总数,即有几个实例执行当前定时任务,
MyFirstJob#execute方法中的shardingContext.getShardingTotalCount()获取到的就是这个值。 - overwrite:是否每次启动的时候覆盖之前的配置,如果设置为 false,则如果修改了 cron 表达式等,重启之后不会生效。
- job-parameter:作业的参数,
MyFirstJob#execute方法中的shardingContext.getJobParameter()获取到的就是这个值。 - sharding-item-parameters:分片的参数,0、1、2 分别表示第几个分片,
MyFirstJob#execute方法中的shardingContext.getShardingParameter()获取到的就是这个值。
好啦,现在就配置完成了。
3. 运行
现在我们直接启动 Spring Boot 项目,启动之后,控制台就会打印如下日志:

没问题,每隔三秒钟打印一次日志。
现在我们再次启动一个当前项目的实例,勾选 Allow parallel run 就可以启动多个实例(启动新实例时记得修改端口号):

当新的实例启动之后,我们发现第一次启动的实例中已经没有打印日志了,转而在第二次启动的实例中打印日志,这就是因为我们配置的 sharding-total-count 为 1,即同一时间只有一个实例中的定时任务在运行。
3. 运维平台
ElasticJob 提供了一个运维平台,可以通过这个平台来动态管理定时任务,运维平台地址:
运维平台使用步骤:
- 克隆项目下来:
git clone https://github.com/apache/shardingsphere-elasticjob-ui.git。 - 进入到目录中:
cd shardingsphere-elasticjob-ui。 - 打包:
mvn clean package -Prelease。 - 打包完成后,解压
shardingsphere-elasticjob-ui/shardingsphere-elasticjob-ui-distribution/shardingsphere-elasticjob-lite-ui-bin-distribution/target/apache-shardingsphere-elasticjob-3.1.0-SNAPSHOT-lite-ui-bin.tar.gz文件,然后执行其 bin 目录下的 startup.sh 脚本启动。
上面第三步打包,由于网络原因很容易出错,所以小伙伴们要是打包失败,可以在公众号江南一点雨后台回复 shardingsphere-elasticjob-ui,获取松哥打包好的文件。
运维平台启动之后,浏览器输入 http://localhost:8088 就会跳转到登录页面,如下:
默认的用户名密码都是 root。
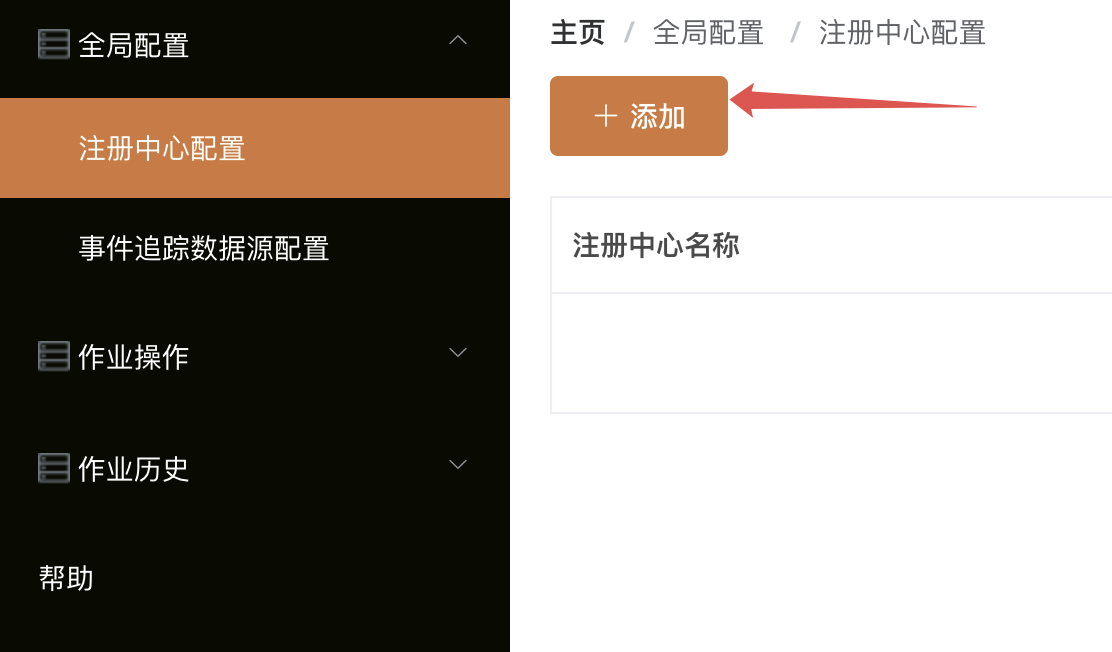
注册成功之后,先点击注册中心配置,然后选择添加按钮,先来添加注册中心,添加完注册中心之后,这个运维平台会自动从注册中心上读取定时任务信息:
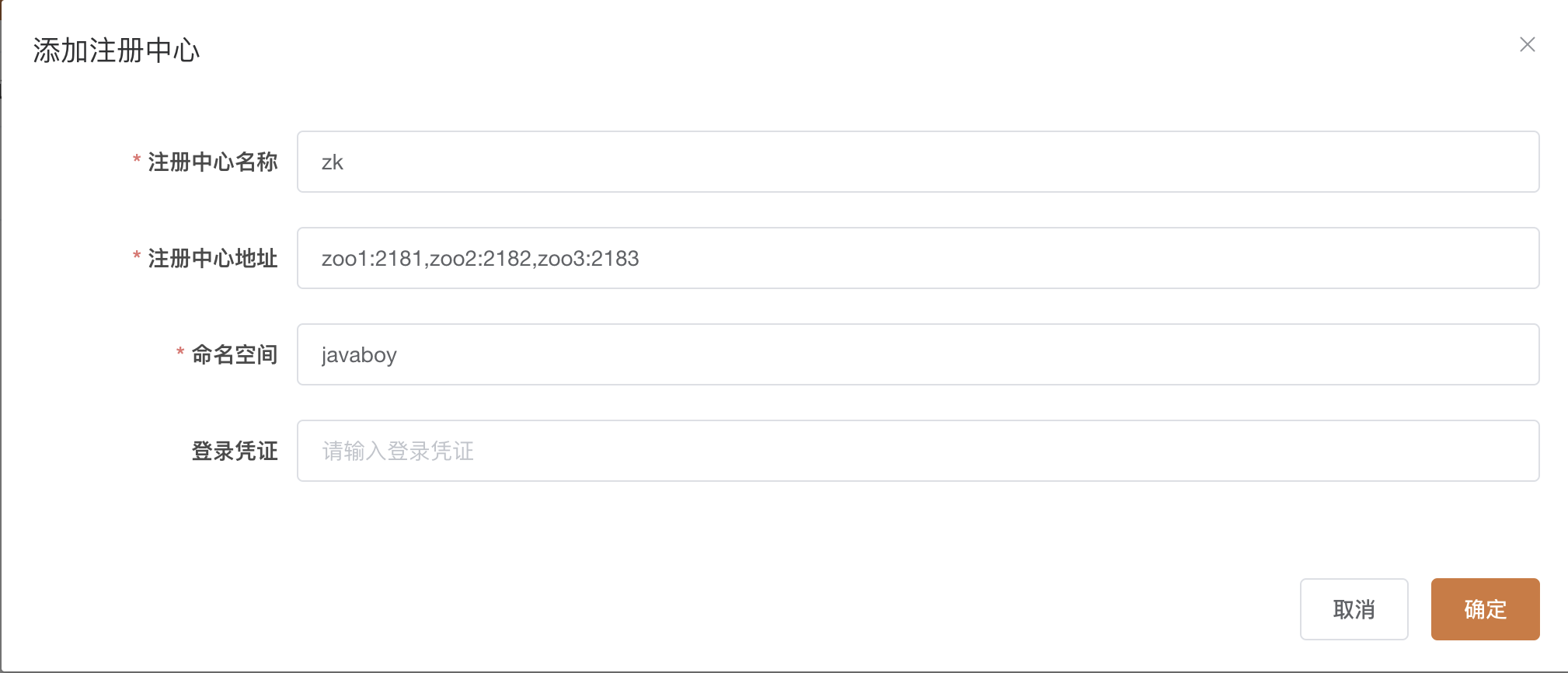
如实填写就行了,注意命名空间千万别写错了,写成了其他的就读取不到定时任务了。
接下来点击连接按钮,建立和 zk 之间的连接:

点击作业维度,就可以查看作业的详细信息,包括作业名称、分片总数、cron 表达式等:

最后面有四个操作按钮:
- 修改:修改作业的详细信息,例如修改作业的 cron 表达式。
- 详情:查看作业的详细信息。
- 触发:触发作业的执行。
- 失效:相当于暂停作业的执行,点击失效按钮之后,会出现生效按钮,点击生效按钮,作业可以生效继续执行。
- 终止:停止该作业。
点击服务器维度,可以查看服务器信息:

4. 小结
好啦,今天就通过一个简单的案例,和小伙伴们展示了一下 ElasticJob 的玩法,关于 ElasticJob 的其他玩法,咱们后面有空继续聊~
