主键索引就是聚集索引?MySQL 索引类型大梳理
[TOC]
之前松哥在前面的文章中介绍 MySQL 的索引时,有小伙伴表示被概念搞晕了,主键索引、非主键索引、聚簇索引、非聚簇索引、二级索引、辅助索引等等,今天咱们就来捋一捋这些概念。
1. 按照功能划分
按照功能来划分,索引主要有四种:
- 普通索引
- 唯一性索引
- 主键索引
- 全文索引
普通索引就是最最基础的索引,这种索引没有任何的约束作用,它存在的主要意义就是提高查询效率。
普通索引创建方式如下:
1 | CREATE TABLE `user` ( |
name 字段就是一个普通索引(括号外面的是索引名,里边的是索引的字段)。
唯一性索引则在普通索引的基础上增加了数据唯一性的约束,一张表中可以同时存在多个唯一性索引,唯一性索引创建方式如下:
1 | CREATE TABLE `user` ( |
name 字段就是唯一性索引。
主键索引则是在唯一性索引的基础上又增加了不为空的约束(换言之,添加了唯一性索引的字段,是可以包含 NULL 值的),即 NOT NULL+UNIQUE,一张表里最多只有一个主键索引,当然一个主键索引中可以包含多个字段。
前面两个例子中都有主键索引的创建方式,我这里就不再列举了。
全文索引其实我们很少在 MySQL 中用,如果项目中有做全文索引的需求,一般可以通过 Elasticsearch 或者 Solr 来做,目前比较流行的就是 Elasticsearch 了,松哥之前也录过专门的视频,公众号后台回复 es 获取教程链接。
全文索引在 MySQL 中支持的版本也需要大家留意一下:
- MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引。
- MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引。
创建全文索引对字段类型也有要求,只有字段的数据类型为 CHAR、VARCHAR 以及 TEXT 等才可以建立全文索引。
MySQL 的全文索引最开始只支持英文,因为英文分词比较方便;中文分词就比较麻烦,所以最早的 MySQL 全文索引是不支持中文的。从 MySQL5.7.6 版本开始,引入了 ngram 全文分析器来解决分词问题,并且这个分词器对 MyISAM 和 InnoDB 引擎都有效。
不过 MySQL 的全文索引并不好用,有这方面的需求还是直接上 Es 吧。
全文索引的创建方式如下:
1 | CREATE TABLE `user` ( |
name 字段就是全文索引。
2. 按照物理实现划分
按照物理实现方式,索引可以分为两大类:
- 聚集索引(有的人也称之为“聚簇索引”)
- 非聚集索引(有的人也称之为“非聚簇索引”)
2.1 聚集索引
聚集索引在存储的时候,可以按照主键(不是必须,看情况)来排序存储数据,B+Tree 的叶子结点就是完整的数据行,查找的时候,找到了主键也就找到了完整的数据行。
如下图,在聚集索引中,叶子结点保存了每一行的数据。
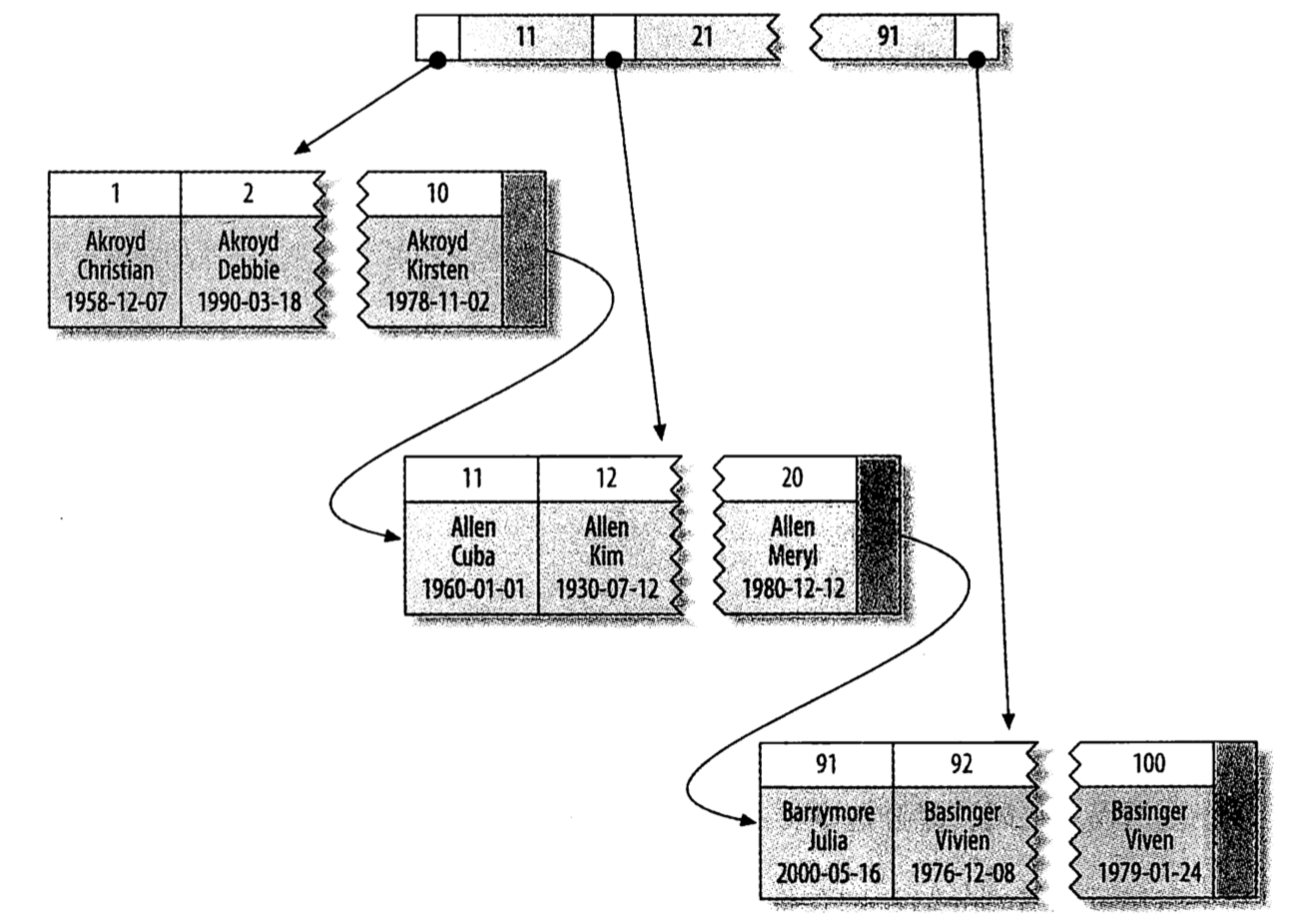
在聚集索引里,表中数据行按索引的排序方式进行存储,对查找行很有效。只有当表包含聚集索引时,表内的数据行才会按找索引列的值在磁盘上进行物理排序和存储。每张表只能有一个聚集索引,原因很简单,因为数据行本身只能按一个顺序存储。
当我们基于 InnoDB 引擎创建一张表的时候,都会创建一个聚集索引,每张表都有唯一的聚集索引:
- 如果这张表定义了主键索引,那么这个主键索引就作为聚集索引。
- 如果这张表没有定义主键索引,那么该表的第一个唯一非空索引作为聚集索引。
- 如果这张表也没有唯一非空索引,那么 InnoDB 内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个 6 个字节的列,该列的值会随着数据的插入自增。
基于以上描述大家可以看到,主键索引和聚集索引并不是一回事,切勿混淆!
聚集索引最主要的优势就是查询快。如果要查询完整的数据行,使用非聚集索引往往需要回表才能实现,而使用聚集索引则能一步到位。
不过聚集索引也有一些劣势:
- 聚集索引可以减少磁盘 IO 的次数,这在传统的机械硬盘中是很有优势的,不过要是固态硬盘或者内存(有时候为了提高操作效率,数据库服务器会整一个比较大的内存),这个优势就不明显了。
- 聚集索引在插入的时候,最好是主键自增,自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);而其他非自增主键插入的时候,可能要插入到两个已有的数据中间,就有可能导致叶子节点分裂等问题,插入效率低(要挪动其他记录)。如果聚集索引在插入的时候不是自增主键,插入效率就会比较低。
2.2 非聚集索引
非聚集索引我们一般也称为二级索引或者辅助索引,对于非聚集索引,数据库会有单独的存储空间来存放。非聚集索引在查找的时候要经过两个步骤,例如执行 select * from user where username='javaboy'(假设 username 字段是非聚集索引),那么此时需要先搜索 username 这一列索引的 B+Tree,这个 B+Tree 的叶子结点存储的不是完整的数据行,而是主键值,当我们搜索完成后得到主键的值,然后拿着主键值再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
所以如果我们在查询中用到了非聚集索引,那么就会搜索两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索聚集索引的 B+Tree,这个过程就是所谓的回表。
一张表只能有一个聚集索引,但可以有多个非聚集索引。使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
3. 小结
总的来说,数据库索引可以按照两种思路来分类:按照功能分和按照存储方式分。
按照功能分,可以分四种:
- 普通索引
- 唯一性索引
- 主键索引
- 全文索引
按照存储方式分,可以分两种:
- 聚集索引
- 非聚集索引
每种之间有区别又有联系,希望上文能为大家解惑,有问题欢迎留言讨论。
