MySQL 多表联合查询有何讲究?
今天我们来聊聊微信中的多表联合查询,应该是小表驱动大表还是大表驱动小表?
1. in VS exists
在正式分析之前,我们先来看两个关键字 in 和 exists。
假设我现在有两张表:员工表和部门表,每个员工都有一个部门,员工表中保存着部门的 id,并且该字段是索引;部门表中有部门的 id、name 等属性,其中 id 是主键,name 是唯一索引。
这里我就直接使用 vhr 中的表来做试验,就不单独给大家数据库脚本了,小伙伴们可以查看 vhr 项目(https://github.com/lenve/vhr)获取数据库脚本。
假设我现在想查询技术部的所有员工,我有如下两种查询方式:
第一种查询方式是使用 in 关键字来查询:
1 | select * from employee e where e.departmentId in(select d.id from department d where d.name='技术部') limit 10; |
这个 SQL 很好理解,相信大家都能懂。查询的时候也是先查询里边的子查询(即先查询 department 表),然后再执行外表的查询,我们可以看下它的执行计划:

可以看到,首先查询部门表,有索引就用索引,没有索引就全表扫描,然后查询员工表,也是利用索引来查询,整体上效率比较高。
第二种是使用 exists 关键字来查询:
1 | select * from employee e where exists(select 1 from department d where d.id=e.departmentId and d.name='技术部') limit 10; |
这条 SQL 的查询结果和上面用 in 关键字的一样,但是查询过程却不一样,我们来看看这个 SQL 的执行计划:

可以看到,这里先对员工表做了全表扫描,然后拿着员工表中的 departmentId 再去部门表中进行数据比对。上面这个 SQL 中,子查询有返回值,就表示 true,没有返回值就表示 false,如果为 true,则这个员工记录就保留下来,如果为 false,则这个员工记录会被抛弃掉。所以在子查询中的可以不用 SELECT *,可以将之改为 SELECT 1 或者其他,MySQL 官方的说法是在实际执行时会忽略SELECT 清单,因此写啥区别不大。
对比两个查询计划中的扫描行数,我们就能大致上看出差异,使用 in 的话,效率略高一些。
如果用 in 关键字查询的话,先部门表再员工表,一般来说部门表的数据是要小于员工表的数据的,所以这就是小表驱动大表,效率比较高。
如果用 exists 关键字查询的话,先员工表再部门表,一般来说部门表的数据是要小于员工表的数据的,所以这就是大表驱动小表,效率比较低。
总之,就是要小表驱动大表效率才高,大表驱动小表效率就会比较低。所以,假设部门表的数据量大于员工表的数据量,那么上面这两种 SQL,使用 exists 查询关键字的效率会比较高。
2. 为什么要小表驱动大表
在 MySQL 中,这种多表联合查询的原理是:以驱动表的数据为基础,通过类似于我们 Java 代码中写的嵌套循环 的方式去跟被驱动表记录进行匹配。
以第一小节的表为例,假设我们的员工表 E 表是大表,有 10000 条记录;部门表 D 表是小表,有 100 条记录。
假设 D 驱动 E,那么执行流程大概是这样:
1 | for 100 个部门{ |
那么查找的总次数是 100+log10000。
假设 E 驱动 D,那么执行流程大概是这样:
1 | for 10000 个员工{ |
那么总的查找次数是 10000+log100。
从这两个数据对比中我们就能看出来,小表驱动大表效率要高。核心的原因在于,搜索被驱动的表的时候,一般都是有索引的,而索引的搜索就要快很多,搜索次数也少。
3. 没有索引咋办?
前面第二小节我们得出的结论有一个前提,就是驱动表和被驱动表之间关联的字段是有索引的,以我们前面的表为例,就是 E 表中保存了 departmentId 字段,该字段对应了 D 表中的 id 字段,而 id 字段在 D 表中是主键索引,如果 id 不是主键索引,就是一个普通字段,那么 D 表岂不是也要做全表扫描了?那个时候 E 驱动 D 还是 D 驱动 E 差别就不大了。
对于这种被驱动表上没有可用索引的情况,MySQL 使用了一种名为 Block Nested-Loop Join (简称 BNL)的算法,这种算法的步骤是这样:
- 把 E 表的数据读入线程内存 join_buffer 中。
- 扫描 D 表,把 D 表中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
小伙伴们来看下,如果我把 E 表中 departmentId 字段上的索引删除,再把 D 表中的 id 字段上的主键索引也删除,此时我们再来看看如下 SQL 的执行计划:

可以看到,此时 E 表和 D 表都是全表扫描,另外需要注意,这些比对操作都是在内存中,所以执行效率都是 OK 的。
但是,既然把数据都读入到内存中,内存中能放下吗?内存中放不下咋办?我们看上面的查询计划,对 E 表的查询中,Extra 中还出现了 Using join buffer (Block Nested Loop),Block 不就有分块的意思吗!所以这意思就很明确了,内存中一次放不下,那就分块读取,先读一部分到内存中,比对完了再读另一部分到内存中。
通过如下指令我们可以查看 join_buffer 的大小:
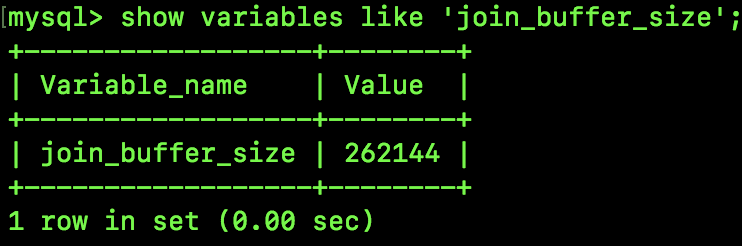
262144/1024=256KB
默认大小是 256 KB。
我现在把这个值改大,然后再查看新的执行计划,如下:

大家看到,此时已经没有 Using join buffer (Block Nested Loop) 提示了。
总结一下:
- 如果 join_buffer 足够大,一次性就能读取所有数据到内存中,那么大表驱动小表还是小表驱动大表都无所谓了。
- 如果 join_buffer 大小有限,那么建议小表驱动大表,这样即使要分块读取,读取的次数也少一些。
不过老实说,这种没有索引的多表联合查询效率比较低,应该尽量避免。
综上所述,在多表联合查询的时候,建议小表驱动大表。
