答读者问:关于隐式 id 重复的问题
我自己天天跟大伙讲 Spring 源码,我基本都是分析源码来讲。小伙伴们学习了之后,经常会产生许多千奇百怪的想法,这些想法都很不错,往往这些想法还给了我很大的启发,让我发现原来这个问题还可以从这个角度来理解。
今天我们来看一个小伙伴的提问:

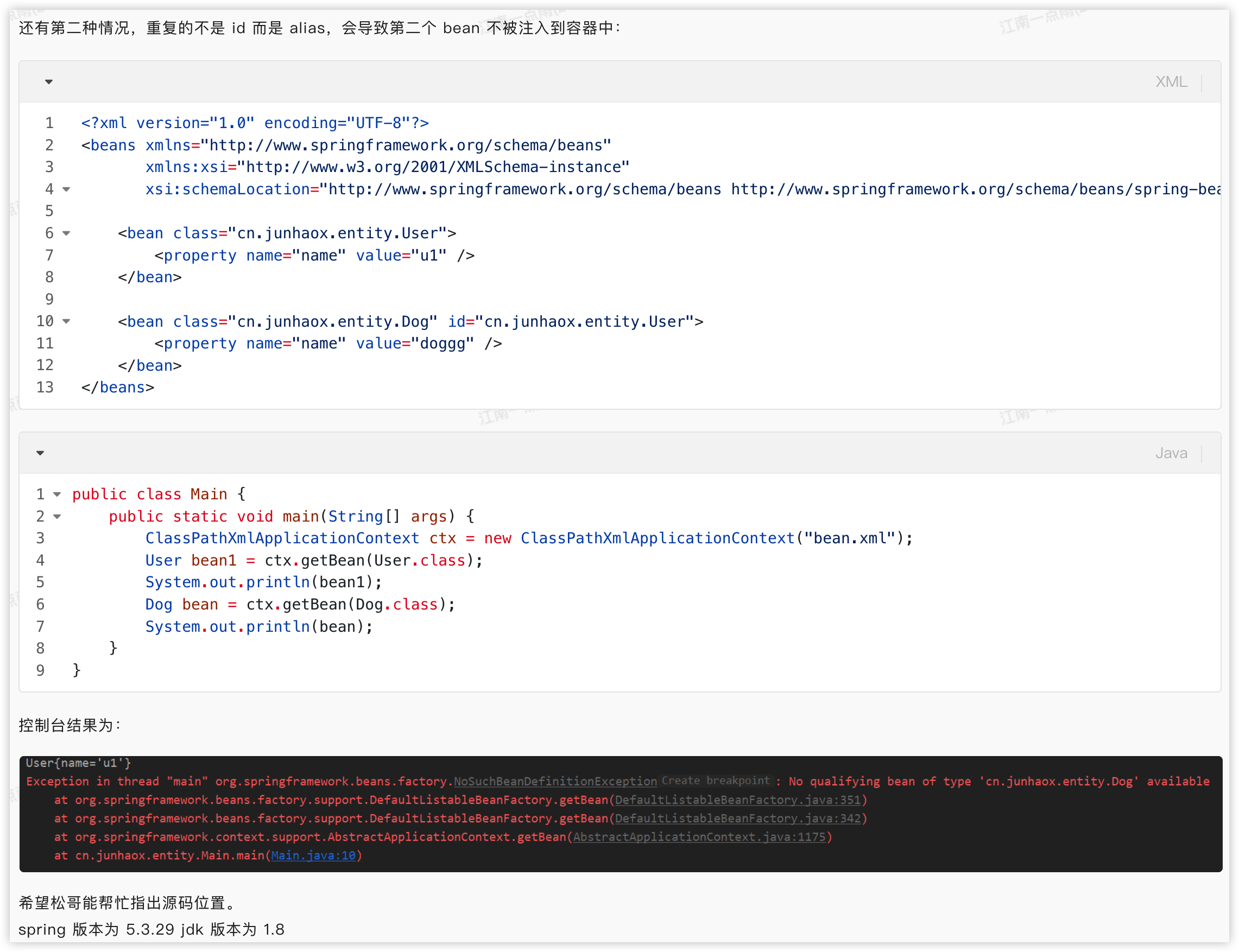
首先我得先夸一句,这个问题真的非常好!问题非常详细,有源码有截图有版本号,该说的都说了,问题非常清晰,我一看就知道发生了什么事情,每天在微信上问松哥问题的人不少,能把问题说的这么清楚的人屈指可数。
我跟大家讲一下这个问题的上下文:
Spring 中 beanName 是不能重复的,一般情况下,我们在定义 Bean 的时候,都要为其指定 beanName 属性,如果不指定,则会默认生成 beanName。在 XML 配置中,如果我们不指定 beanName 或者 id,那么默认生成的 beanName 就是类名的完整路径或者是 类名完整路径+#+编号。这个小伙伴就是在学习了上述内容之后,提出来这个问题。
关于 beanName 自动生成逻辑松哥在视频中都已经详细介绍过了,因此这里就简单和大家梳理一下思路,具体可以参考 Spring 源码视频。
问题分析
小伙伴一共提出两个问题,我们分别来看。
问题一
首先定义了一个 User 对象,但是并未指定 beanName,按照松哥之前在 Spring 源码视频中所讲的,此时会自动给这个 bean 生成 id 和别名,别名是类名的完整路径,即 cn.junhaox.entity.User,id 则是类名完整路径+编号,即 cn.junhaox.entity.User#0,即我们可以通过这两个任意一个名称来访问到第一个对象。
第二个 bean 在定义的时候,则指定了 id,而且指定的 id 恰好就是第一个 bean 自动生成的 id。
这个逻辑上显然是冲突了,导致最终访问的时候,通过 cn.junhaox.entity.User#0 或者 cn.junhaox.entity.User 访问到的是第二个 bean 而不是第一个 bean,这就给人一种第一个 bean 似乎注册失败了的感觉。
我们先来分析一下这个问题。
先来说 bean 的注册,当 bean 在注册的时候,首先会去检查当前 beanName 是否重复(具体在 org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseBeanDefinitionElement(org.w3c.dom.Element, org.springframework.beans.factory.config.BeanDefinition) 方法中),但是这个检查主要是检查我们自己手动配置的 beanName 是否存在重复的情况,并不会去检查自动生成的 beanName 是否重复,这就导致了当第二个 bean 在注册的时候,检查 beanName 是否重复的时候,结果发现 beanName 并不重复,因此就导致了 cn.junhaox.entity.User#0 beanName 重新指向了第二个 bean,那毫无疑问,cn.junhaox.entity.User 作为别名,也重新指向了第二个 bean。
这就是第一个问题产生的原因。
问题二
根据前面的分析,小伙伴们已经知道,对于第一个 bean,由于即没有配置 id,又没有配置 beanName,所以第一个 bean 在注册的时候,会自动生成 id cn.junhaox.entity.User#0 并且会自动生成 beanName cn.junhaox.entity.User。
现在第二个问题就是把第一个 bean 的别名作为第二个 bean 的 id 了,导致第二个 bean 似乎访问不到了。
松哥先来说结论,这个问题其实目前在最新版的 Spring 中已经不存在了,具体的处理是在 2022 年 2 月 5 号提交的代码中解决了问题,在当年 3 月份发布的 v6.0.0-M3 版本中这块的代码改过来了,我们来看下代码的变化大家就明白了:
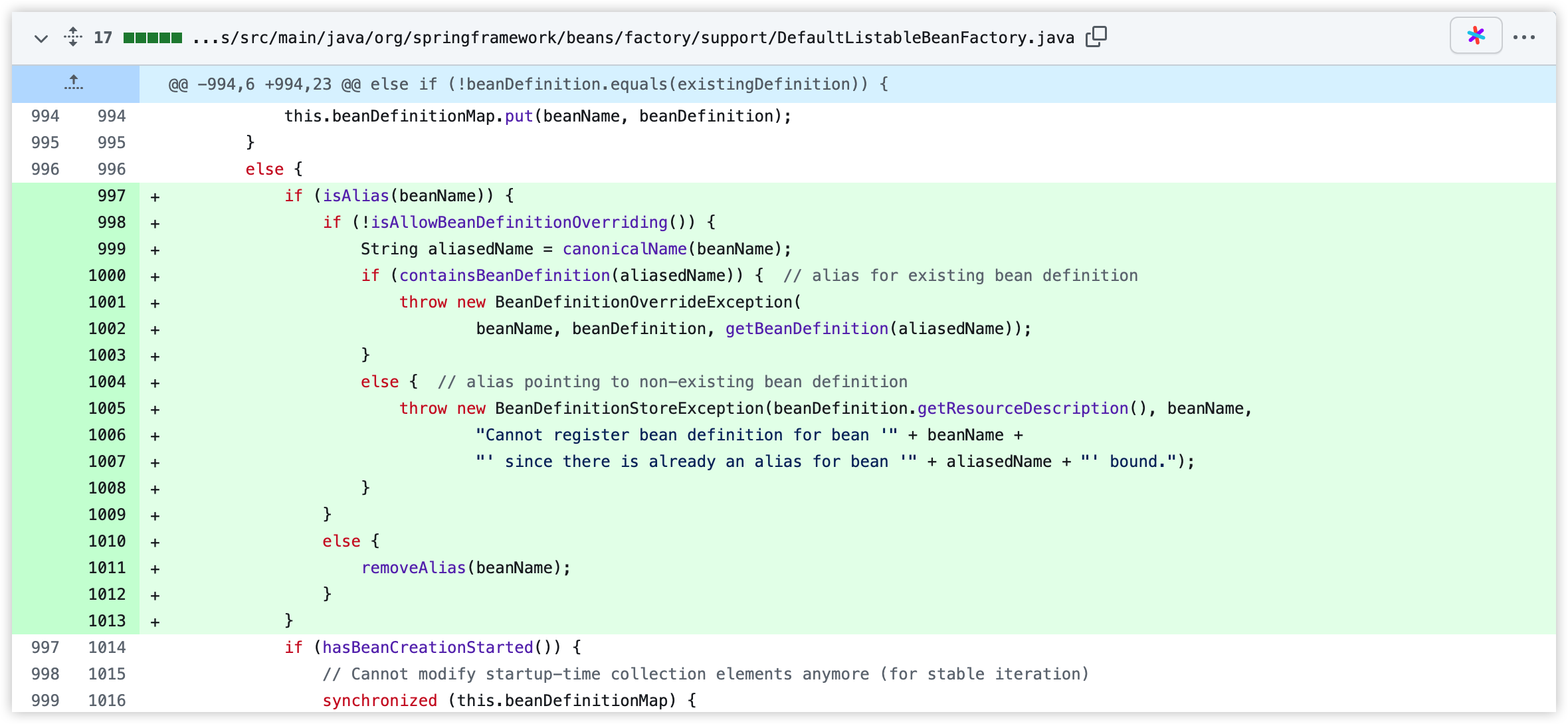
大家可以看到,变化发生在 DefaultListableBeanFactory#registerBeanDefinition 方法中,绿色的代码块就是新增的代码。
新增的代码主要是当我们向容器注册一个 BeanDefinition 的时候,首先会去检查这个 beanName 是否是一个别名,如果是,则检查别名是否允许覆盖,如果别名不允许覆盖,那么该抛异常就抛异常,如果别名允许覆盖,则调用 removeAlias 方法移除别名,这个移除相当于剪掉了别名之间的关系,cn.junhaox.entity.User 将不再作为别名指向 cn.junhaox.entity.User#0 了。
因此,对于第二个问题,从 Spring6.0.0-M3 开始,通过 cn.junhaox.entity.User#0 可以访问到第一个 bean,通过 cn.junhaox.entity.User 则可以访问到第二个 bean。
但是,在此版本之前,并未检查当前 beanName 是否是一个别名,而是直接使用该 beanName 进行注册。当我们去查询 bean 的时候,都是根据 beanName 去查找 bean 的,如果是根据类型,最终也会先根据类型找出 beanName,然后再去查找 bean。根据 beanName 去搜索 bean 的时候,会先根据别名链条确定出最终的 beanName,由于 cn.junhaox.entity.User 和 cn.junhaox.entity.User#0 之间还存在别名关系,因此当我们按照 beanName cn.junhaox.entity.User 去搜索 bean 的时候,系统会找到这是 cn.junhaox.entity.User#0 的别名,进而找出来 cn.junhaox.entity.User#0 所对应的 bean 并返回,这就导致第二个 bean 将来无法被查找到。
好啦,现在这两个问题都搞明白了吧~
以上内容松哥主要是和大家分享思路,技术细节包括涉及到的 Spring 源码细节在之前的 Spring 视频中都讲过,大家可以参考视频。
欢迎大家继续提问!
