九道深信服面试题
有小伙伴反馈的最近面试深信服遇到的几个“棘手”问题,松哥来和大家简单聊一聊。
一 MySQL 只有 CPU 高,怎么优化
这道问题是当发现 MySQL 的 CPU 飙高,该如何优化?从哪些方面思考入手。
数据库优化是个大学问,对症下药尤为重要。
如果是 CPU 飙高的话,我们首先可以通过 SHOW PROCESSLIST; 来查看正在运行的线程,类似下面这样:
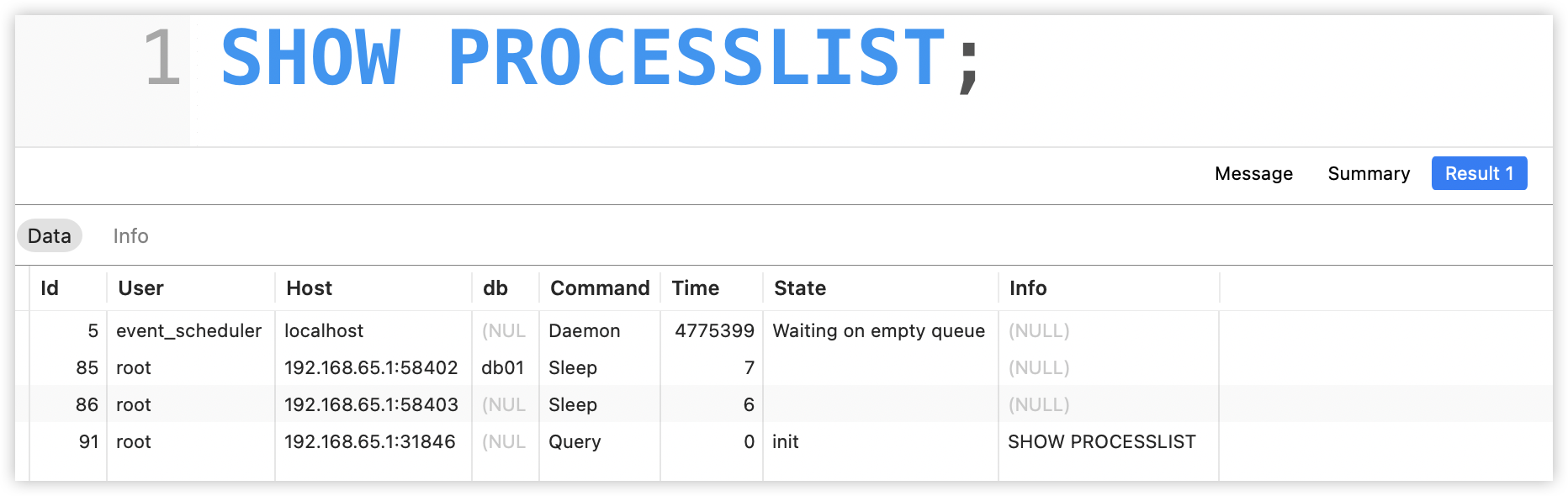
接下来可以根据这个表格进行排查。
首先找到 Time 这列,找出来 Time 执行时间过长的 SQL。
接下来查看这条 SQL 的 State,根据 State 的提示我们可以做出不同的决策。
例如:
- State 为 Locked 就表示当前操作被其他查询锁住了。
- State 为 Sending Data 就表示正在处理 SELECT 查询记录,同时正在把结果发送给客户端。
- State 为 Sleeping 表示正在等待客户端发送新请求。
- …
还有很多状态,面试时候能回答常见的几个即可。
在这个检查中,我们可能会发现存在的一些死锁、或者是由于无索引/索引不合理导致的搜索速度变慢,我们可以根据实际情况解决。
另外有时候我们在执行 SHOW PROCESSLIST; 之后,可能会发现 Command 中存在很多 Sleep,这就说明当前连接数过多,这也会影响到 MySQL 的执行效率。
那么对于这种问题,我们可以设置等待超时时间,超时之后自动断开,配置方式如下:
1 | # vim /etc/my.cnf |
配置完成后重启 MySQL。
如果不想重启 MySQL 解决这个问题,可以使用如下两条命令去解决:
1 | # 设置超时等待时间 |
设置完成之后,再去检查 CPU 使用率是否有下降。
二 MySQL 本身缓存怎么优化
这个题目据小伙伴描述,有一个限制条件就是 MySQL 自身的缓存如何优化,而不是问外部缓存(如 Redis)优化问题,并且面试官也强调了他们使用的是 MySQL5.7。
为什么强调是 MySQL5.7 呢?因为在最新版的 MySQL8 中,查询缓存已经不再支持了。
查询缓存存储了 SELECT 语句的文本,以及发送给客户端的相应结果。如果后来收到一个相同的语句,服务器会从查询缓存中检索结果,而不是再次解析和执行该语句。查询缓存是在会话之间共享的,因此一个客户端产生的结果集可以被用来响应另一个客户端发出的相同查询。如果你有一些不经常变化的表,而服务器收到许多相同的查询,查询缓存在这样的环境中很有用。
所以咱就说说 MySQL5.7 中的查询缓存吧。
首先要确认下查询缓存是否开启了,在 MySQL5.7.2 中,查询缓存默认是关闭状态,查询方式如下:
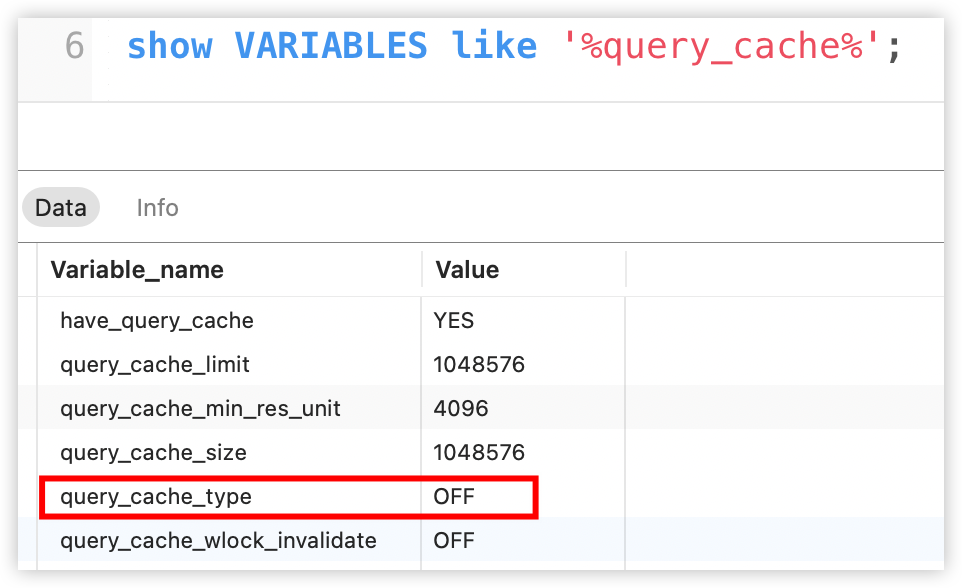
如果是关闭状态,我们可以在配置文件中添加如下属性来开启:
1 | query_cache_type=1 |
接下来执行 show status like 'qcache%'; 命令来查看缓存相关信息:
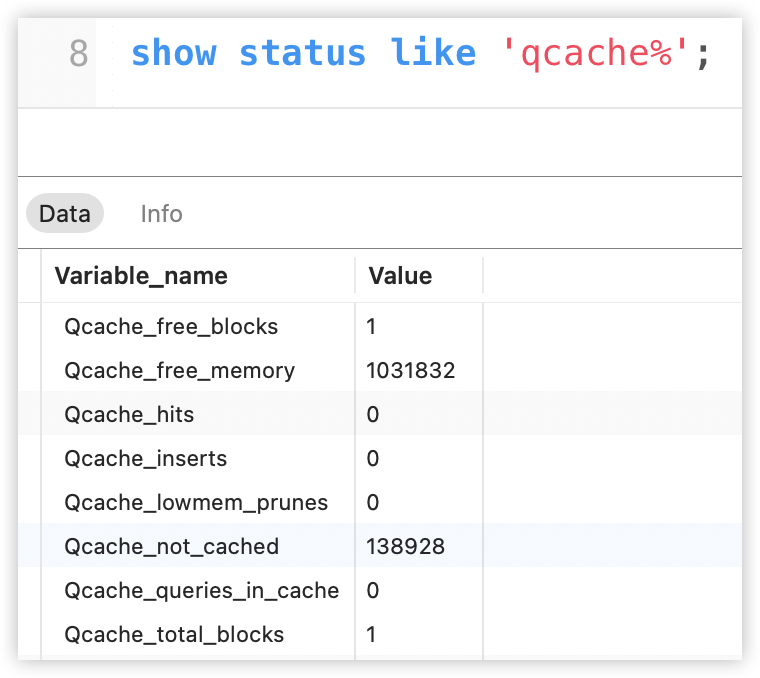
那么这里有一个参数值得关注:
- Qcache_free_blocks:这个表示查询缓存中目前还有多少剩余的 blocks,如果该值显示较大,则说明查询缓存中的内存碎片过多了,可能需要对内存进行整理了,整理可以使用
flush query cache指令。
减少内存碎片的一个方案就是在 MySQL 的配置文件中设置合适的 query_cache_min_res_unit,这个就是最小的内存分配单元。一般来说,可以将其设置为缓存平均内存大小,缓存平均大小的计算方式是这样:
(query_cache_size-Qcache_free_memory)/Qcache_queries_in_cache
设置完成后可以再运行一段时间观察内存碎片是否有减少。
三 类的加载过程
这个前面文章讲过了,这里不再赘述。
四 硬件配置提升了,反而 OOM
具体问题是说硬件配置原本是 2C4G,后来升级为 8C16G,升级之后反而发生了 OOM,硬件升级前没问题。
老实说这个问题松哥还没想出来一个合理的解释,如果单是 8C16G 的硬件配置发生 OOM,这个简单,问题是 2C4G 可以正常运行,8C16G 却 OOM。。。
这道题欢迎小伙伴们在评论区给出自己的见解~
五 JMeter 关注哪些信息
JMeter 我们经常用它做压测,那么在压测结束后主要关注哪些指标信息呢?
- Samples/样本:这个就是请求总数,比如并发是 100,循环次数是 100,那么样本数就是
100*100。 - Average/平均值:这个是平均响应时间。
- Error/异常:测试出现的错误请求数量百分比。
- Throughput/吞吐量:这个就是每秒处理的事务数,一般与具体的事务相关。如果这个值大于并发数,那么可以尝试增加并发数后再次测试,如果增加了并发数该值反而下降,那就说明并发数达到峰值了。
一般主要关注这几个指标。
六 线程池核心数怎么配置
通用公式是:
- CPU 密集型:N+1
- IO 密集型:2N+1
不过这种答案面试官一般不会满意。
一般线程池核心数我们可以根据实际情况进行计算后配置,例如我们可以统计一个完整的请求中,耗费 CPU 计算的过程占用了多少时间,等待的过程(例如读取缓存、读取 DB 等)占用了多少时间,假设我们的统计结果是 100ms 用来做 CPU 计算,900ms 都是 IO 相关不占 CPU 时间,那么我们就可以通过 (100+900)/100 的计算公式,得出,对于单核 CPU,设置线程数为 10 可以把 CPU 跑满,同理,如果是 8 核 CPU,那么就设置线程数为 80。
七 无监控,不调优
这道问题是接着上面一道题问的,面试官表示线程池线程数的设置是个难题,他希望能够动态调整线程池线程数,并能够看到调整后的效果(线程利用率),问有无这样的工具能够实现这样的效果。
这个问题松哥在前面的文章中和大家聊过了,参见:
八 有无具体用过 Arthas
这个问题其实很好回答,但是如果你从来没用过 Arthas,那么不妨看下松哥的这篇文章,虽然讲的是插件,但是插件生成的命令也和大家详细解释了:
九 IP 配置问题
局域网内有两台设备,其中一个 IP 地址是 192.168.1.100,另一个 IP 地址是 192.168.2.100,如何让这两台设备在局域网通信?
这个问题在网络领域里边属于入门级问题,但是很多人长期做软件开发有可能忘记了网络知识,就导致回答不出来。
这个主要是配置一下子网掩码,设置子网掩码为 255.255.0.0,这样就能确保如上两个 IP 处于同一个网段中,就可以通信了。
